Superskalär CPU — definition och hur instruktionsparallellism fungerar
Upptäck vad en superskalär CPU är och hur instruktionsparallellism och flera funktionella enheter ökar prestanda — tydlig definition och praktiska exempel.
En superskalär CPU-design utnyttjar parallell beräkning på instruktionsnivå (instruction-level parallelism, ILP) i en enda processor för att öka mängden arbete som utförs vid en given klockfrekvens. I praktiken betyder det att CPU:n kan starta och/eller slutföra mer än en instruktion per klockcykel genom att köra flera instruktioner samtidigt på flera funktionella enheter. Dessa funktionella enheter kan vara exempelvis en aritmetisk-logisk enhet (ALU), en flyttalsenhet (FPU), en multiplikator eller specialiserade enheter för skiftning och SIMD-operationer.
Bildgalleri
2 Bilder
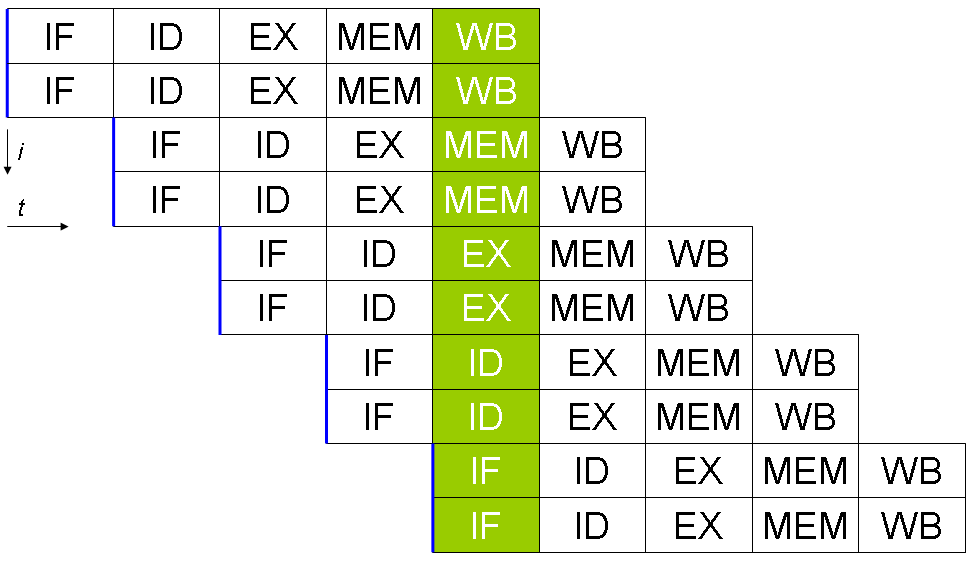
Hur instruktionsparallellism fungerar
I en superskalär processor läser en instruktionsfördelare (instruction dispatcher/issue logic) en sekvens av instruktioner och bestämmer vilka av dessa som kan exekveras parallellt utan att skapa fel på grund av beroenden eller delade resurser. För att detta ska fungera krävs flera stödjande mekanismer i hårdvaran:
- Instruktioner kommer från en ordnad instruktionslista.
- CPU-hårdvaran kan räkna ut vilka instruktioner som har vilka databeroenden.
- Kan läsa flera instruktioner per klockcykel
Dessa egenskaper gör att flera instruktioner som är oberoende av varandra kan skickas ("issued") till olika funktionella enheter, vilket ökar instruktionsnivåns parallellism (ILP) och därmed potentiellt ökar instruktioner per klockcykel (IPC).
Viktiga tekniker och komponenter
- Pipelining: De flesta superskalära processorer är också pipelinerade. Pipelining delar upp varje instruktion i flera steg (fetch, decode, execute, write-back) så flera instruktioner kan befinna sig i olika steg samtidigt.
- Utanför-ordning-exekvering (out-of-order execution): Hårdvaran kan ibland köra instruktioner i annan ordning än programordningen för att utnyttja fria resurser och dölja latens.
- Registeromdöpning (register renaming): Förhindrar falska beroenden (anti- och utberoenden) genom att dynamiskt tilldela fysiska register så att logiska register inte kolliderar.
- Grenförutsägelse (branch prediction): Förbättrar flödet i pipelinen genom att korrekt gissa vilken väg ett villkorligt hopp kommer att ta, vilket minskar kostsamma pipeline-stall.
- Instruktionsfönster och omordningsbuffert: Ett fönster av instruktioner hålls i en buffert så att fördelaren kan välja och skicka instruktioner som är redo att exekveras; en omordningsbuffert (reorder buffer) säkerställer att resultat skrivs tillbaka i programordning vid behov.
- Strukturella resurser: Duplicerade funktionella enheter (flera ALU:er, FPU:er, SIMD-enheter) krävs för verklig parallell exekvering. Om resurserna inte räcker uppstår strukturella konflikter som begränsar prestandan.
Skillnad mot skalär-, vektor- och VLIW-arkitekturer
En traditionell skalär processor utför en eller ibland två instruktioner per cykel (beroende på bredd). En vektor- eller SIMD-processor behandlar däremot många dataelement inom en enda instruktion (data-parallellism). Superskalär arkitektur kombinerar idéerna genom att:
- Varje instruktion behandlar i regel ett dataelement (skalär beteende).
- Det finns flera duplicerade funktionella enheter i varje CPU-kärna, så att flera instruktioner som arbetar på oberoende data kan hanteras samtidigt.
Det finns också en viktig distinktion mellan dynamisk superskalär (hårdvaran bestämmer schemaläggningen i realtid) och statisk parallellism som i VLIW (där kompilatorn ansvarar för att placera instruktioner parallellt). VLIW förenklar hårdvaran men lägger större krav på kompilatorn och har mindre flexibilitet vid dynamiska beroenden.
Begränsningar och utmaningar
Att öka graden av superskaläritet ger inte linjär prestandavinster oändligt. Följande faktorer begränsar hur mycket parallellism man praktiskt kan utnyttja:
- Databeroenden: Sekventiella beroenden mellan instruktioner (data hazards) förhindrar att instruktioner körs samtidigt.
- Kontrollberoenden: Oförutsägbara hopp och dålig branch prediction leder till pipeline-stall och reducerad IPC.
- Minnessystemets latens: Långsam åtkomst till cache eller minne kan blockera exekvering och minska användningen av funktionella enheter.
- Strukturella konflikter: Brist på duplicerade resurser för vissa operationer tvingar instruktioner att vänta.
- Komplexitet och kostnad: Ökad hårdvara för att hantera beroendeanalys, registeromdöpning och omordning ökar kiselarea, effektförbrukning och designkomplexitet.
Mätning av prestanda
Prestandan hos en superskalär CPU mäts ofta i instruktioner per cykel (IPC). IPC tillsammans med klockfrekvens (GHz) bestämmer den teoretiska beräkningskapaciteten. Men praktisk IPC beror starkt på programkodens natur (parallellism, branch-fördelning, minnesåtkomstmönster) samt CPU:ns förmåga att hålla enheter sysselsatta.
Praktiska exempel och historik
Från omkring 1990-talet och framåt har många allmänna processorer (x86, ARM m.fl.) använt superskalär design kombinerad med pipelining, branch prediction och out-of-order-exekvering. En typisk modern superskalär kärna kan ha flera ALU:er, ett par FPU:er och specialiserade SIMD-enheter. Om instruktionsfördelaren inte lyckas hålla dessa enheter upptagna, reduceras CPU:ns praktiska prestanda.
Sammanfattning
En superskalär CPU ökar instruktionsnivåns parallellism genom att skicka flera instruktioner samtidigt till olika funktionella enheter. För att detta ska ge verklig vinst krävs avancerad hårdvara för att upptäcka och hantera beroenden, stöd för pipelining, registeromdöpning, branchförutsägelse och ofta out-of-order-exekvering. Begränsningar som beroenden, branches och minneslatens gör att det finns avtagande avkastning vid att lägga till fler exekveringsenheter, men i praktiken är superskalär arkitektur grunden i majoriteten av dagens allmänna CPU:er.


Begränsningar
Prestandaförbättringar i Superscalar CPU-design begränsas av två saker:
- Nivån på inbyggd parallellism i instruktionslistan.
- Komplexiteten och tidsåtgången för dispatcher och kontroll av databeroendet.
Även om oändligt snabb kontroll av beroenden i en normal superskalär CPU, om instruktionslistan i sig har många beroenden, skulle detta också begränsa den möjliga prestandaförbättringen, så mängden inbyggd parallellism i koden är en annan begränsning.
Oavsett hur snabb dispatcherna är finns det en praktisk gräns för hur många instruktioner som kan skickas samtidigt. Även om utvecklingen av maskinvaran kommer att möjliggöra fler funktionella enheter (t.ex. ALU:er) per CPU-kärna, ökar problemet med att kontrollera instruktionsberoenden till en gräns som gör att gränsen för superskalär dispatching blir något liten. -- Troligen i storleksordningen fem till sex samtidigt skickade instruktioner.
Alternativ
- Simultaneous multithreading, ofta förkortat SMT, är en teknik för att förbättra den totala hastigheten hos superskalära CPU:er. SMT gör det möjligt att utföra flera oberoende trådar för att bättre utnyttja de tillgängliga resurserna i en modern superskalär processor.
- Flerkärniga processorer: superskalära processorer skiljer sig från flerkärniga processorer genom att de flera redundanta funktionella enheterna inte är hela processorer. En enda superskalär processor består av avancerade funktionella enheter som ALU, heltalsmultiplikator, heltalsskiftare, floating point unit (FPU) osv. Det kan finnas flera versioner av varje funktionell enhet för att möjliggöra utförande av många instruktioner parallellt. Detta skiljer sig från en flerkärnig processor som samtidigt bearbetar instruktioner från flera trådar, en tråd per kärna.
- Pipelineprocessorer: superskalära processorer skiljer sig också från en pipelineprocessor, där flera instruktioner samtidigt kan vara i olika stadier av utförande.
De olika alternativa teknikerna utesluter inte varandra - de kan kombineras (och kombineras ofta) i en enda processor, så det är möjligt att konstruera en flerkärnig CPU där varje kärna är en oberoende processor med flera parallella superskalära pipelines. Vissa flerkärniga processorer har också vektorkapacitet.
Relaterade sidor
- Parallell beräkning
- Parallellism på instruktionsnivå
- Simultan multitrådning (SMT)
- Processorer med flera kärnor
Frågor och svar
F: Vad är superskalär teknik?
S: Superskalär teknik är en form av grundläggande parallell beräkning som gör det möjligt att behandla mer än en instruktion i varje klockcykel genom att använda flera exekveringsenheter samtidigt.
F: Hur fungerar superskalär teknik?
S: Superskalär teknik innebär att instruktionerna kommer in till processorn i tur och ordning, att den letar efter databeroenden medan den körs och laddar mer än en instruktion i varje klockcykel.
F: Vad är skillnaden mellan skalära och vektorprocessorer?
S: I en skalär processor arbetar instruktionerna vanligtvis med en eller två dataelement samtidigt, medan instruktionerna i en vektorprocessor vanligtvis arbetar med många dataelement samtidigt. En superskalär processor är en blandning av båda, eftersom varje instruktion behandlar ett dataelement, men mer än en instruktion körs samtidigt så att många dataelement hanteras samtidigt av processorn.
F: Vilken roll spelar en noggrann instruktionsfördelare i en superskalär processor?
S: En noggrann instruktionsfördelare är mycket viktig för en superskalär processor eftersom den ser till att exekveringsenheterna alltid är upptagna med arbete som sannolikt kommer att behövas. Om instruktionsfördelaren inte är exakt kan en del av arbetet behöva kastas bort, vilket skulle göra den inte snabbare än en skalär processor.
F: Vilket år blev alla normala CPU:er superskalära?
Svar: Alla normala CPU:er blev superskalare 2008.
Fråga: Hur många ALU:er, FPU:er och SIMD-enheter kan det finnas i en normal CPU?
S: På en normal CPU kan det finnas upp till 4 ALU:er, 2 FPU:er och 2 SIMD-enheter.
Relaterade artiklar
Författare
AlegsaOnline.com Superskalär CPU — definition och hur instruktionsparallellism fungerar Leandro Alegsa
URL: https://sv.alegsaonline.com/art/95080