Cache-algoritmer: principer, vanliga strategier och praktiska överväganden
Översikt av cache-algoritmer: mått som träfffrekvens och latens, optimala och approximativa strategier (Belady, LRU, LFU, ARC med flera), implementeringsfrågor och användning i praktiken.
Översikt
En cache-algoritm avgör vilka objekt som ska sparas eller tas bort i ett cacheminne när utrymmet är begränsat. Syftet är att öka systemets prestanda genom att maximera sannolikheten att en begäran kan betjänas direkt från cachen istället för från en långsammare källa. Nyckelmått för att bedöma en cache är träfffrekvens (hit rate), som anger andelen begäranden som leder till träff i cachen, samt latens, som beskriver tiden från förfrågan till leverans av ett objekt från cachen. I praktiska system är valet av algoritm ofta en kompromiss mellan att optimera träfffrekvens, minimera latens och hålla administrativa kostnader för uppföljning och uppdatering av metadata låga. För mer allmän information om hur man hanterar en cache kan man konsultera vidare läsning som riktar sig mot arkitektur- och systemdesign.
Bildgalleri
7 Bilder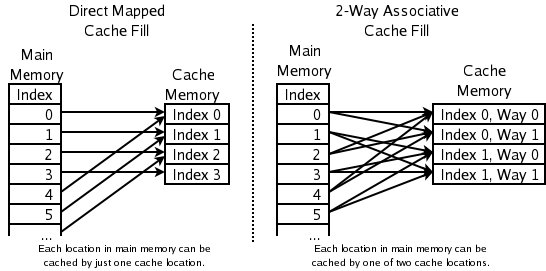



Optimalt mål och vanliga strategier
Det teoretiska optimala beteendet för en cache är att alltid kasta det objekt som inte kommer att behövas förrän längst fram i tiden — detta kallas ibland Beladys optimala algoritm eller "den klarsynta" algoritmen. Eftersom framtida åtkomstmönster i praktiska system vanligtvis inte är helt förutsägbara, används i stället heuristiska eller adaptiva algoritmer som ger goda resultat utan att kräva kunskap om framtiden. Nedan följer en översikt över de mest använda strategierna och deras huvuddrag:
- LRU (Least Recently Used) — Kastas de objekt som inte använts på längst tid. LRU bygger på antagandet att nyligen använda data sannolikt kommer användas igen. Det kan implementeras exakt med en länkad lista eller tidsstämplar, men dessa metoder medför overhead i tid och minne. LRU förekommer i många varianter och optimeringar, exempelvis LRU/K och 2Q, för att hantera skillnader mellan kort- och långsiktig återanvändning.
- MRU (Most Recently Used) — Motsatsen till LRU: den senast använda posten rensas först. MRU kan vara effektivt i scenarier där nyligen åtkomna objekt troligen inte kommer att användas igen, exempelvis vissa databascacher som behandlar sekventiella skanningar.
- LFU (Least Frequently Used) — Räknar åtkomstfrekvens och tar bort de minst använda objekten. LFU fungerar bra när belastningen präglas av stabila, ofta återkommande heta objekt, men kan vara trögt att anpassa vid snabba förändringar i åtkomstmönstret.
- Pseudo-LRU (PLRU) — En approximativ version av LRU som kräver mindre metadata. PLRU är vanligt i hårdvarucachar där minnes- och tidskostnaderna måste hållas minimala; den markerar ungefär vilka linjer som är minst nyligen använda utan fullständig ordning.
- Associativa och direktmappade metoder — I praktiken för CPU-cacher är direktmappad cache och N-vägs set-associativitet vanliga. Vid 2-vägs associativ cache väljs den minst nyligen använda av två kandidater för ersättning; direktmappad cache har deterministisk plats för varje adress och ersätter vad som finns där utan jämförelse.
- Adaptiva och hybridmetoder — ARC (Adaptive Replacement Cache) och algoritmer som MQ försöker kombinera styrkorna hos LRU och LFU genom att anpassa sig över tiden efter arbetsmönstrets karaktär. Dessa metoder kan ofta ge bättre prestanda över en bredare uppsättning arbetslaster genom att dynamiskt byta betoning mellan frekvens och nylighet.
Implementering och praktiska överväganden
Val av algoritm påverkas starkt av implementeringskostnader: att hålla fullständig historik för LRU kan innebära stor overhead i synkrona system eller i hårdvarunära cachelösningar, medan enklare heuristiker eller bit-baserade representationer (som i PLRU) minskar kostnaden men också precisionen. Vid design bör man också beakta att objekt kan ha olika storlek, varierande kostnad att hämta, och utgångsdatum (time-to-live). En cache som innehåller objekt av olika storlek kan behöva kostnadsbaserade eller storleksbaserade ersättningsregler: det kan vara bättre att kasta ett enda stort objekt för att frigöra plats åt flera små men ofta använda objekt. Likaså kan objekt som är dyra att generera eller hämta (t.ex. beräknade data, långa databasfrågor eller nätverksanrop) prioriteras högre i cachen.
Användningsområden och exempel
Cache-algoritmer används i många nivåer i moderna system: processorns nivå 1–3 caches använder ofta hårdvaruoptimerade varianter av LRU eller direktmappning; operativsystem och databashanterare har buffertpooler med LRU-liknande eller adaptiva strategier; webbläsare, proxytjänster och CDN:er använder TTL (time-to-live) tillsammans med ersättningslogik för att både begränsa lagringsutrymme och säkerställa färskhet. DNS-cachar och webbapplikationers data- eller sessionscachar kombinerar ofta enkel tidsbaserad utgång med en ersättningsstrategi för hantering när utrymmet tar slut. För exempel på cachestrategier i databasmiljöer kan man läsa mer om hur databascachar och buffertpooler implementeras.
Särskilda fall, förlängningar och att tänka på
I distribuerade eller parallella miljöer uppstår ytterligare krav: flera oberoende cacheminnen som lagrar samma data måste ofta hålla informationen koherent så att uppdateringar blir synliga för alla parter. Olika protokoll och algoritmer för cachekoherens används för detta ändamål beroende på arkitekturens krav och kan ha betydande påverkan på prestanda och komplexitet; se vidare material om cachekoherens. I vissa system är det också vanligt att använda hierarkiska cachar eller flera nivåer av cachar (till exempel L1/L2/L3 i CPU:er eller klient-/server-/CDN-nivå i nätverk) där olika algoritmer kan passa bättre på olika nivåer beroende på latens- och kostnadsrestriktioner.
Jämförelser och slutliga råd
Det finns ingen universellt bästa algoritm: valet beror på arbetsmönstret, objektens karaktär och systemets krav på latens och overhead. En tumregel är att börja med en enkel och väletablerad strategi (till exempel en LRU-variant) och sedan mäta verklig prestanda under riktiga arbetsbelastningar; om mönstret visar stabil hetta eller snabba skiftningar kan en LFU, ARC eller annan adaptiv metod vara motiverad. För experiment och jämförelser kan man också mäta hur nära en given strategi kommer den teoretiska optimala kurvan (Belady) genom att simulera historiska åtkomstloggar och utvärdera skillnaden i träfffrekvens. Ytterligare läsning om principer för latens och utbytbarhet finns under ämnen som latensoptimering och prestandaanalys, och för mer formella algoritmbeskrivningar och varianter av LRU se resurser om Belady och relaterade algoritmer.
Sammanfattningsvis är cache-algoritmer centrala för många system som vill kombinera begränsad lagringskapacitet med höga prestandakrav. Genom att förstå grundläggande antaganden (nylighet vs. frekvens), mäta riktiga åtkomstmönster och balansera administrativa kostnader blir det möjligt att välja eller anpassa en algoritm som ger god praktisk effekt i den specifika miljön.

Frågor och svar
Fråga: Vad är en cachealgoritm?
S: En cachealgoritm är en algoritm som används för att hantera en cache eller en grupp av data. Den bestämmer vilket objekt som ska tas bort från cacheminnet när det är fullt.
F: Vad är träfffrekvens?
S: Träfffrekvens beskriver hur ofta en begäran kan betjänas från cacheminnet.
F: Vad beskriver latenstid?
S: Latency beskriver hur länge en cachad artikel kan hämtas.
F: Vad är Beladys optimala algoritm?
S: Beladys optimala algoritm, även känd som den klärvoajanta algoritmen, är en effektiv caching-algoritm som alltid kastar bort den information som inte kommer att behövas under den längsta tiden i framtiden. Detta resultat kan i allmänhet inte tillämpas i praktiken eftersom det kräver att man förutsäger vad som kommer att behövas långt in i framtiden.
F: Hur fungerar LRU (Least Recently Used)?
S: LRU raderar de minst nyligen använda objekten först och kräver att man håller reda på vad som användes när genom att använda "åldersbitar" för varje cachelinje och spåra vilken linje som användes minst nyligen baserat på åldersbitar. Varje gång en cachelinje används ändras alla andra cachelinjers ålder i enlighet med detta.
Fråga: Hur fungerar MRU (Most Recently Used)?
S: MRU raderar de senast använda objekten först, och denna cachemekanism används ofta för minnescacher i databaser.
F: Vilka andra algoritmer finns det för att upprätthålla cachekohärens?
S: Det finns olika algoritmer för att upprätthålla cachekoherens när flera oberoende cacheminnen används för delade data, t.ex. när flera databasservrar uppdaterar en enda delad datafil.
Relaterade artiklar
Författare
AlegsaOnline.com Cache-algoritmer: principer, vanliga strategier och praktiska överväganden Leandro Alegsa
URL: https://sv.alegsaonline.com/art/15882
Källor
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org