Mikroarkitektur (CPU): definition, funktion och skillnad mot ISA
Utforska mikroarkitektur för CPU: hur kretsar och design styr prestanda, funktioner och skillnader mot ISA — klar och praktisk guide till datorarkitektur och processororganisation.
Inom datateknik är mikroarkitektur (ibland förkortat µarch eller uarch) en beskrivning av de elektriska kretsarna i en dator, central processorenhet eller digital signalprocessor som är tillräcklig för att fullständigt beskriva maskinvarans funktion.
Forskare använder termen "datororganisation" medan människor inom datorindustrin oftare använder termen "mikroarkitektur". Mikroarkitektur och instruktionsuppsättningsarkitektur (ISA) utgör tillsammans området datorarkitektur.
Bildgalleri
1 Bild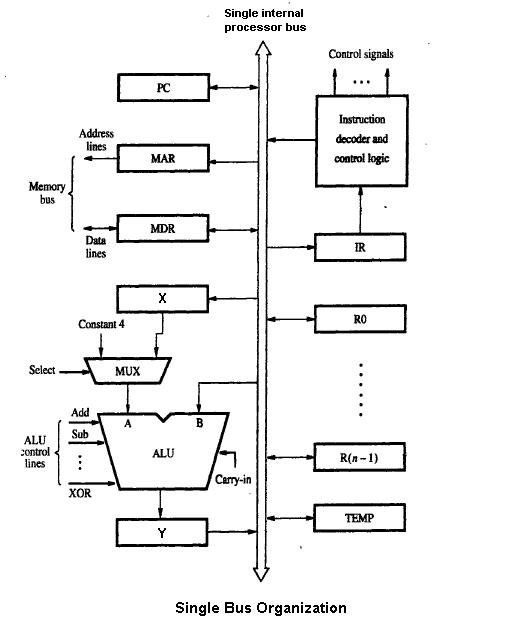
Definition och syfte
Mikroarkitektur beskriver hur en processor eller annan digital enhet är uppbyggd i termer av dess interna komponenter och kretsar — till exempel datapaths, kontrolllogik, register, buffrar, pipeline-steg och kopplingar till minne och I/O. Syftet är att beskriva den konkreta implementeringen som realiserar en given ISA eller annan funktionsspecifikation. Mikroarkitekturen svarar för att översätta instruktioner och program till elektriska signaler som styr beräkningar och dataflöde i hårdvaran.
Hur mikroarkitektur fungerar (översikt)
- Instruktionsflöde: Instruktioner hämtas från minnet, avkodas och omvandlas till operationer som ska utföras av exekveringsenheter.
- Datapath: Innehåller aritmetisk/logisk enhet (ALU), flyttalsenheter, registerfiler och multiplexrar som flyttar data mellan enheter.
- Kontrollen: Styrlogik (hård-kodad eller mikroprogrammerad) koordinerar sekvenser av operationer och hanterar signalerna för varje steg.
- Pipeline och parallellism: Många moderna mikroarkitekturer använder pipelining (delning av instruktionens steg i flera stadier) och andra former av parallellism (superskalar, SIMD, SMT) för att öka genomströmningen.
- Minnehierarki: Cacheminnen, TLB, och minneskontrollers placering och parametrar påverkar latens och bandbredd.
- Spekulation: Grenprediktion och out-of-order-execution används för att utnyttja lediga exekveringsenheter effektivt.
Skillnaden mellan mikroarkitektur och ISA
Det är viktigt att skilja mellan ISA (instruktionsuppsättningsarkitektur) och mikroarkitektur:
- ISA: Är programmerarens synliga gränssnitt — instruktioner, register, adresseringslägen och undantagsbeteende. ISA specificerar vad processorn gör ur ett program-perspektiv.
- Mikroarkitektur: Är implementeringen av ISA i hårdvara. Den beskriver hur ISA:ns beteende uppnås genom kretsar, pipeline-steg, buffertar och kontrolllogik.
- Flera mikroarkitekturer per ISA: Samma ISA kan implementeras på många olika sätt. Exempel: olika x86‑mikroarkitekturer från Intel och AMD implementerar samma x86‑ISA men med olika pipeline-djup, cachestorlekar, och exekveringsenheter.
- Kompatibilitet och innovation: En kompatibel mikroarkitektur måste uppfylla ISA:s semantik, men den kan vara optimerad för prestanda, energiförbrukning eller kostnad genom olika designval.
Implementationsdetaljer och varianter
- Hård-kodad kontroll vs mikroprogram: Vissa processorer använder mikroprogram (microcode) som nivå för att tolka komplexa instruktioner; andra är helt hardwired för snabbare, enklare instruktioner.
- RISC vs CISC: RISC‑arkitekturer tenderar mot enklare instruktioner och enklare mikroarkitektur per instruktion, medan CISC kan kräva mikroprogram eller intern översättning av komplexa instruktioner till enklare mikro-operationer.
- Out-of-order execution: Tillåter instruktioner att exekveras i annan ordning än den programmerbara ordningen för att öka utnyttjande av exekveringsenheter.
- Superskalaritet och fler kärnor: Superskalar mikroarkitektur kan utföra flera instruktioner per klockcykel; moderna system kombinerar detta med flera kärnor för parallellism på programnivå.
Prestanda, kraft och designval
Design av mikroarkitektur handlar om kompromisser mellan prestanda, energikonsumtion, kostnad och komplexitet. Exempel på påverkan:
- Djupare pipelines och aggressiv spekulation kan ge hög klockfrekvens men ökar straffet vid felprediktioner.
- Större och flerskiktade cacheminnen förbättrar prestanda men ökar area och effektförbrukning.
- Out-of-order-mekanismer ökar IPC (instructions per cycle) men kräver komplex register- och beroendehantering.
Utveckling, verifiering och verktyg
Mikroarkitektur designas ofta i HDL (t.ex. Verilog eller VHDL) på RTL-nivå, simuleras och verifieras formellt eller med testbänkar innan syntes till kisel. Verktyg för samband mellan ISA och mikroarkitektur inkluderar assembler, mikrocode-verktyg, simulators (t.ex. gem5) och formella verifierare.
Moderna trender
- Ökad fokus på energibesparing och effektivitetsorienterad design (ARM, mobilprocessorer).
- Heterogena system där CPU-kärnor kombineras med acceleratorer (GPU, NPU) för specifika uppgifter.
- Fortlöpande förbättringar inom grenprediktion, minnessubsystem och säkerhetsmekanismer (t.ex. mitigering av spekulativa attacker).
Sammanfattning
Mikroarkitektur är den konkreta hårdvaruimplementeringen som får en processor att bete sig enligt en given ISA. Den omfattar allt från datapaths, kontroll, pipeline-stadier och cache till strategier för parallellism och spekulation. Medan ISA definierar vad en processor gör, beskriver mikroarkitekturen hur det görs — och det finns många möjliga mikroarkitekturer som kan implementera samma ISA beroende på mål för prestanda, kostnad och energieffektivitet.
Begreppets ursprung
Datorer har använt mikroprogrammering av styrlogik sedan 1950-talet. CPU:n avkodar instruktionerna och skickar signaler längs lämpliga vägar med hjälp av transistorbrytare. Bitarna i mikroprogramorden styrde processorn på nivån för elektriska signaler.
Termen mikroarkitektur användes för att beskriva de enheter som styrdes av mikroprogramorden, till skillnad från termen: "arkitektur" som var synlig och dokumenterad för programmerare. Medan arkitekturen vanligtvis måste vara kompatibel mellan olika hårdvarugenerationer, kunde den underliggande mikroarkitekturen lätt ändras.
Förhållande till instruktionsuppsättningsarkitektur
Mikroarkitekturen är relaterad till, men inte densamma som, instruktionsuppsättningsarkitekturen. Arkitekturen för instruktionsuppsättningen ligger nära programmeringsmodellen för en processor som den ses av en programmerare eller kompilatorförfattare, vilket inkluderar exekveringsmodellen, processorregister, minnesadresslägen, adress- och dataformat osv. Mikroarkitekturen (eller datororganisationen) är huvudsakligen en struktur på lägre nivå och hanterar därför ett stort antal detaljer som är dolda i programmeringsmodellen. Den beskriver processorns inre delar och hur de arbetar tillsammans för att genomföra den arkitektoniska specifikationen.
Mikroarkitektroniska element kan vara allt från enskilda logiska grindar till register, uppslagstabeller, multiplexer, räknare osv. till kompletta ALU:er, FPU:er och ännu större element. Den elektroniska kretsnivån kan i sin tur delas upp i detaljer på transistornivå, t.ex. vilka grundläggande strukturer för grindkonstruktion som används och vilka typer av logikimplementering (statisk/dynamisk, antal faser osv.) som väljs, utöver den faktiska logikdesign som används för att bygga dem.
Några viktiga punkter:
- En enda mikroarkitektur, särskilt om den innehåller mikrokod, kan användas för att genomföra många olika instruktionsuppsättningar genom att ändra kontrolllagret. Detta kan dock vara ganska komplicerat, även om det förenklas av mikrokod och/eller tabellstrukturer i ROM:er eller PLA:er.
- Två maskiner kan ha samma mikroarkitektur, och därmed samma blockdiagram, men helt olika hårdvaruimplementationer. Detta gäller både den elektroniska kretsen och i ännu högre grad den fysiska tillverkningsnivån (av både integrerade kretsar och/eller diskreta komponenter).
- Maskiner med olika mikroarkitekturer kan ha samma instruktionssatsarkitektur, och båda kan därför köra samma program. Nya mikroarkitekturer och/eller kretslösningar, tillsammans med framsteg inom halvledartillverkning, är det som gör att nyare generationer av processorer kan uppnå högre prestanda.
Förenklade beskrivningar
En mycket förenklad beskrivning på hög nivå - som är vanlig inom marknadsföring - kan visa endast ganska grundläggande egenskaper, t.ex. bussbredd, tillsammans med olika typer av exekveringsenheter och andra stora system, t.ex. grenförutsägelser och cacheminnen, som är avbildade som enkla block - kanske med några viktiga attribut eller egenskaper noterade. Vissa detaljer om pipeline-strukturen (t.ex. hämta, avkoda, tilldela, utföra, skriva tillbaka) kan ibland också inkluderas.
Aspekter av mikroarkitektur
Den pipelinerade datapaden är den vanligaste datapatdesignen i dagens mikroarkitektur. Denna teknik används i de flesta moderna mikroprocessorer, mikrokontroller och DSP:er. Pipelined-arkitekturen gör det möjligt för flera instruktioner att överlappa varandra i utförandet, ungefär som i ett löpande band. Pipeline innehåller flera olika steg som är grundläggande i mikroarkitekturkonstruktioner. Några av dessa steg är hämta instruktioner, avkoda instruktioner, utföra och skriva tillbaka. Vissa arkitekturer innehåller andra steg, t.ex. minnesåtkomst. Utformningen av pipelines är en av de centrala mikroarkitekturuppgifterna.
Exekveringsenheter är också viktiga för mikroarkitekturen. Exekveringsenheterna omfattar aritmetiska logikenheter (ALU), flyttalsenheter (FPU), laddnings- och lagringsenheter och grenförutsägelser. Dessa enheter utför processorns operationer eller beräkningar. Valet av antalet exekveringsenheter, deras latenstid och genomströmning är viktiga uppgifter vid utformningen av mikroarkitekturen. Storlek, latens, genomströmning och anslutningsmöjligheter för minnen i systemet är också mikroarkitektoniska beslut.
Beslut om utformning på systemnivå, t.ex. om man ska inkludera kringutrustning, t.ex. minneskontroller, kan betraktas som en del av mikroarkitekturutformningsprocessen. Detta inbegriper beslut om prestandanivå och anslutningsmöjligheter för dessa periferier.
Till skillnad från arkitektonisk design, där en viss prestandanivå är huvudmålet, är mikroarkitekturdesign mer uppmärksam på andra begränsningar. Uppmärksamhet måste ägnas åt frågor som t.ex:
- Chip-yta/kostnad.
- Strömförbrukning.
- Logisk komplexitet.
- Lätt att ansluta.
- Tillverkningsbarhet.
- Lätt att felsöka.
- Testbarhet.
Koncept för mikroarkitektur
I allmänhet kör alla CPU:er, mikroprocessorer med ett chip eller multichip-implementationer, program genom att utföra följande steg:
- Läsa en instruktion och avkoda den.
- Hitta all tillhörande data som behövs för att bearbeta instruktionen.
- Bearbeta instruktionen.
- Skriv ut resultaten.
Det faktum att minneshierarkin, som omfattar caching, huvudminne och icke-flyktiga lagringsutrymmen som hårddiskar (där programinstruktionerna och data finns), alltid har varit långsammare än själva processorn försvårar denna enkla serie av steg. Steg (2) innebär ofta en fördröjning (i CPU-termer ofta kallad "stall") medan data anländer över datorbussen. Mycket forskning har lagts ned på konstruktioner som undviker dessa fördröjningar så mycket som möjligt. Under årens lopp har ett centralt konstruktionsmål varit att utföra fler instruktioner parallellt och därmed öka den effektiva utföringshastigheten för ett program. Genom dessa ansträngningar infördes komplicerade logik- och kretsstrukturer. Tidigare kunde sådana tekniker endast genomföras på dyra stordatorer eller superdatorer på grund av den mängd kretsar som krävdes för dessa tekniker. I takt med att halvledartillverkningen utvecklades kunde allt fler av dessa tekniker genomföras på ett enda halvledarchip.
Nedan följer en översikt över mikroarkitekturtekniker som är vanliga i moderna CPU:er.
Val av instruktionsuppsättning
Valet av vilken arkitektur för instruktionsuppsättning som ska användas påverkar i hög grad komplexiteten i implementeringen av högpresterande enheter. Under årens lopp har datorkonstruktörerna gjort sitt bästa för att förenkla instruktionsuppsättningarna för att möjliggöra implementeringar med högre prestanda genom att spara tid och kraft för funktioner som förbättrar prestandan i stället för att slösa bort dem på instruktionsuppsättningens komplexitet.
Designen av instruktionsuppsättningar har utvecklats från CISC-, RISC-, VLIW- och EPIC-typer. Arkitekturer som behandlar dataparallelism omfattar SIMD och vektorer.
Pipelining av instruktioner
En av de första och mest kraftfulla teknikerna för att förbättra prestandan är användningen av instruktionspipeline. Tidiga processorkonstruktioner utförde alla ovanstående steg på en instruktion innan de gick vidare till nästa. Stora delar av processorkretsarna var inaktiva vid varje enskilt steg; till exempel skulle instruktionsavkodningskretsarna vara inaktiva under utförandet och så vidare.
Pipelines förbättrar prestandan genom att ett antal instruktioner kan arbeta sig genom processorn samtidigt. I samma grundläggande exempel skulle processorn börja avkoda (steg 1) en ny instruktion medan den senaste instruktionen väntar på resultat. Detta skulle göra det möjligt för upp till fyra instruktioner att "flyga" samtidigt, vilket skulle göra processorn fyra gånger så snabb. Även om varje enskild instruktion tar lika lång tid att slutföra (det finns fortfarande fyra steg), "tar processorn som helhet bort" instruktionerna mycket snabbare och kan köras med en mycket högre klockfrekvens.
Cache
Förbättringar i chiptillverkningen gjorde det möjligt att placera fler kretsar på samma chip, och konstruktörerna började leta efter sätt att använda dem. Ett av de vanligaste sätten var att lägga till en allt större mängd cacheminne på chipet. Cache är ett mycket snabbt minne, ett minne som kan nås på några få cykler jämfört med vad som krävs för att prata med huvudminnet. Processorn innehåller en cache-kontroller som automatiserar läsning och skrivning från cacheminnet. Om uppgifterna redan finns i cacheminnet "dyker de helt enkelt upp", medan om de inte finns där "stannar" processorn medan cache-kontrollern läser in dem.
RISC-konstruktionerna började lägga till cacheminne i mitten och slutet av 1980-talet, ofta med endast 4 KB totalt. Detta antal ökade med tiden och typiska CPU:er har nu cirka 512 KB, medan mer kraftfulla CPU:er har 1 eller 2 eller till och med 4, 6, 8 eller 12 MB, organiserade i flera nivåer av en minneshierarki. Generellt sett innebär mer cache högre hastighet.
Caches och pipelines var perfekt anpassade till varandra. Tidigare var det inte särskilt meningsfullt att bygga en pipeline som kunde köras snabbare än åtkomstlatensiteten för kontantminne utanför chipet. Att istället använda on-chip cacheminne innebar att en pipeline kunde köras med samma hastighet som cacheminnets åtkomstlatens, en mycket kortare tid. Detta gjorde det möjligt att öka processorernas driftfrekvenser i en mycket snabbare takt än off-chip-minnet.
Förutsägelse av grenar och spekulativt utförande
Pipeline stalls och flushes på grund av förgreningar är de två största hindren för att uppnå högre prestanda med hjälp av parallellism på instruktionsnivå. Från det att processorns instruktionsavkodare har upptäckt att den har stött på en villkorlig förgrening till dess att det avgörande hoppregistervärdet kan läsas ut kan pipelinen stå stilla i flera cykler. I genomsnitt är var femte utförd instruktion en förgrening, så det är en stor mängd fördröjning. Om förgreningen genomförs är det ännu värre, eftersom alla efterföljande instruktioner som fanns i pipelinen måste spolas.
Tekniker som grenförutsägelse och spekulativt utförande används för att minska dessa grenförluster. Förutsägelse av förgrening innebär att maskinvaran gör kvalificerade gissningar om huruvida en viss förgrening kommer att tas. Gissningen gör det möjligt för maskinvaran att förinhämta instruktioner utan att vänta på registeravläsning. Spekulativt utförande är en ytterligare förbättring där koden längs den förutspådda vägen exekveras innan man vet om förgreningen ska tas eller inte.
Utförande i fel ordning
Tillägget av cacheminnen minskar frekvensen eller varaktigheten av de stopp som beror på att man väntar på att data ska hämtas från huvudminneshierarkin, men gör att dessa stopp inte försvinner helt och hållet. I tidiga konstruktioner tvingade en cachemiss cachekontrollanten att stoppa processorn och vänta. Naturligtvis kan det finnas någon annan instruktion i programmet vars data finns tillgängliga i cacheminnet vid den tidpunkten. Genom att utföra en instruktion i fel ordning kan den färdiga instruktionen bearbetas medan en äldre instruktion väntar i cacheminnet, och sedan ordna om resultaten så att det ser ut som om allt hände i den programmerade ordningen.
Superskalär
Trots all den extra komplexitet och de grindar som behövdes för att stödja de koncept som beskrivs ovan, gjorde förbättringar i halvledartillverkningen det snart möjligt att använda ännu fler logiska grindar.
I skissen ovan bearbetar processorn delar av en enda instruktion i taget. Datorprogrammen kan utföras snabbare om flera instruktioner behandlas samtidigt. Detta är vad superskalära processorer uppnår genom att replikera funktionella enheter som ALU:er. Replikering av funktionella enheter blev möjlig först när den integrerade kretsen (ibland kallad "die") för en processor med en enda processor inte längre sträckte sig över gränserna för vad som kunde tillverkas på ett tillförlitligt sätt. I slutet av 1980-talet började superskalära konstruktioner komma ut på marknaden.
I moderna konstruktioner är det vanligt att det finns två laddningsenheter, en lagringsenhet (många instruktioner har inga resultat att lagra), två eller fler helhetsmatematiska enheter, två eller fler flyttalsenheter och ofta en SIMD-enhet av något slag. Logiken för utfärdande av instruktioner ökar i komplexitet genom att läsa in en enorm lista med instruktioner från minnet och överlämna dem till de olika utförarenheter som är inaktiva vid den tidpunkten. Resultaten samlas sedan in och ordnas på nytt i slutet.
Omdöpning av register
Registeromdöme är en teknik som används för att undvika onödig seriell exekvering av programinstruktioner på grund av att samma register återanvänds av dessa instruktioner. Anta att vi har två grupper av instruktioner som kommer att använda samma register, en uppsättning instruktioner utförs först för att lämna registret till den andra uppsättningen, men om den andra uppsättningen tilldelas ett annat liknande register kan båda uppsättningarna av instruktioner utföras parallellt.
Multiprocessing och multithreading
På grund av det växande gapet mellan CPU:s arbetsfrekvenser och DRAM-åtkomsttiderna kunde ingen av de tekniker som förbättrar parallelliteten på instruktionsnivå (ILP) inom ett program övervinna de långa fördröjningar som uppstod när data måste hämtas från huvudminnet. Dessutom krävde de stora transistorerna och de höga driftfrekvenser som krävs för de mer avancerade ILP-teknikerna effektförluster som inte längre kunde kylas på ett billigt sätt. Av dessa skäl har nyare generationer av datorer börjat utnyttja högre nivåer av parallellism som existerar utanför ett enskilt program eller en programtråd.
Denna trend kallas ibland för "throughput computing". Denna idé har sitt ursprung på stordatormarknaden där man vid online-transaktionsbehandling inte bara betonade hastigheten för en transaktion utan även förmågan att hantera ett stort antal transaktioner samtidigt. Eftersom transaktionsbaserade tillämpningar, t.ex. nätverksdirigering och webbtjänster, har ökat kraftigt under det senaste decenniet har datorindustrin återigen betonat frågor om kapacitet och genomströmning.
En teknik för att uppnå denna parallellitet är multiprocessorssystem, dvs. datorsystem med flera CPU:er. Tidigare var detta förbehållet avancerade stordatorer, men nu har småskaliga servrar med flera processorer (2-8) blivit vanliga på marknaden för småföretag. För stora företag är storskaliga (16-256) multiprocessorer vanliga. Även persondatorer med flera processorer har dykt upp sedan 1990-talet.
Framsteg inom halvledartekniken minskade transistorstorleken; flerkärniga CPU:er har dykt upp där flera CPU:er implementeras på samma kiselchip. Ursprungligen användes de i chip som var avsedda för inbyggda marknader, där enklare och mindre CPU:er skulle göra det möjligt att placera flera instantieringar på en enda kiselbit. År 2005 gjorde halvledartekniken det möjligt att tillverka CMP-chips med dubbla högkvalitativa processorer för skrivbordsmaskiner i stora volymer. Vissa konstruktioner, t.ex. UltraSPARC T1, använde en enklare konstruktion (skalär, i ordning) för att få plats med fler processorer på en kiselbit.
På senare tid har en annan teknik som har blivit alltmer populär varit multithreading. När processorn måste hämta data från ett långsamt systemminne, växlar processorn till ett annat program eller en annan programtråd som är redo att köras i stället för att vänta på att datan ska komma fram. Även om detta inte snabbar upp ett visst program/en viss tråd, ökar det systemets totala genomströmning genom att minska den tid som processorn är inaktiv.
Begreppsmässigt är multitrådning likvärdigt med en kontextväxling på operativsystemsnivå. Skillnaden är att en processor med flera trådar kan göra ett trådbyte på en CPU-cykel i stället för de hundratals eller tusentals CPU-cykler som ett kontextbyte normalt kräver. Detta åstadkoms genom att replikera den maskinvara som används för tillståndet (t.ex. registerfilen och programräknaren) för varje aktiv tråd.
Ytterligare en förbättring är samtidig multitrådning. Denna teknik gör det möjligt för superskalära CPU:er att utföra instruktioner från olika program/trådar samtidigt i samma cykel.
Relaterade sidor
- Mikroprocessor
- Mikrokontroller
- Processor med flera kärnor
- Digital signalprocessor
- CPU-utformning
- Datapath
- parallellism på instruktionsnivå (ILP)
Frågor och svar
Fråga: Vad är mikroarkitektur?
S: Mikroarkitektur är en beskrivning av de elektriska kretsarna i en dator, central processorenhet eller digital signalprocessor som är tillräcklig för att fullständigt beskriva maskinvarans funktion.
F: Hur hänvisar forskare till detta begrepp?
S: Forskare använder termen "datororganisation" när de talar om mikroarkitektur.
F: Hur hänvisar människor i datorbranschen till detta begrepp?
S: Människor i datorbranschen säger oftare "mikroarkitektur" när de hänvisar till detta begrepp.
F: Vilka två områden utgör datorarkitektur?
S: Mikroarkitektur och instruktionsuppsättningsarkitektur (ISA) utgör tillsammans området datorarkitektur.
F: Vad står ISA för?
S: ISA står för Instruction Set Architecture.
F: Vad står µarch för? S: µArch står för mikroarkitektur.
Relaterade artiklar
Författare
AlegsaOnline.com Mikroarkitektur (CPU): definition, funktion och skillnad mot ISA Leandro Alegsa
URL: https://sv.alegsaonline.com/art/64586
Källor
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture