RAID – komplett guide: definition, nivåer, fördelar och risker
RAID – komplett guide: Definition, RAID‑nivåer, fördelar och risker. Lär dig skapa säkra, presterande lagringslösningar med jämförelser, tips och vanliga fallgropar.
Innehåll
· 1 Inledning
o 1.1 Skillnaden mellan fysiska diskar och logiska diskar
o 1.2 Läsa och skriva data
o 1.3 Vad är RAID?
o 1.4 Varför använda RAID?
o 1.5 Historia
· 2 Grundläggande begrepp som används i RAID-system
o 2.1 Cachelagring
o 2.2 Spegling: Mer än en kopia av data.
o 2.3 Remsor: Delar av data finns på en annan disk.
o 2.4 Felkorrigering och fel
o 2.5 Hot spares: att använda fler diskar än vad som behövs
o 2.6 Stripe size och chunk size: Spridning av data över flera diskar
o 2.7 Sätta ihop en skiva: JBOD, concatenation eller spanning
o 2.8 Kloning av enheter
o 2.9 Olika uppställningar
· 3 Grunder: enkla RAID-nivåer
o 3.1 RAID-nivåer som används allmänt
§ 3.1.1 RAID 0 "Striping"
§ 3.1.2 RAID 1 "spegling"
§ 3.1.3 RAID 5 "Striping med distruberad paritet"
§ 3.1.4 Bilder
o 3.2 RAID-nivåer som används mindre ofta
§ 3.2.1 RAID 2
§ 3.2.2 RAID 3 "Striping med dedikerad paritet"
§ 3.2.3 RAID 4 "Striping med dedikerad paritet"
§ 3.2.4 RAID 6
§ 3.2.5 Bilder
o 3.3 Icke-standardiserade RAID-nivåer
§ 3.3.1 Dubbel paritet / Diagonal paritet
§ 3.3.2 RAID-DP
§ 3.3.3 RAID 1.5
§ 3.3.4 RAID 5E, RAID 5EE och RAID 6E
§ 3.3.5 RAID 7
§ 3.3.6 Intel Matrix RAID
§ 3.3.7 Linux MD RAID-drivrutin för MD
§ 3.3.8 RAID Z
§ 3.3.9 Bilder
· 4 Sammanslagning av RAID-nivåer
· 5 Skapa en RAID
o 5.1 RAID-programvara
o 5.2 Maskinvaru-RAID
o 5.3 Maskinvaruunderstödd RAID
· 6 Olika termer för maskinvarufel
o 6.1 Antal misslyckanden
o 6.2 Medeltid till dataförlust
o 6.3 Medeltid till återhämtning
o 6.4 Icke återställbar bitfelfrekvens
· 7 Problem med RAID
o 7.1 Lägga till diskar vid en senare tidpunkt
o 7.2 Kopplade fel
o 7.3 Atomicitet
o 7.4 Uppgifter som inte kan återställas
o 7.5 Tillförlitlighet för skrivcache
o 7.6 Utrustningens kompatibilitet
· 8 Vad RAID kan och inte kan göra
o 8.1 Vad RAID kan göra
o 8.2 Vad RAID inte kan göra
· 9 Exempel
· 10 Referenser
· 11 Andra webbplatser
RAID är en akronym som står för Redundant Array of Inexpensive Disks eller Redundant Array of Independent Disks. RAID är en term som används inom datateknik. Med RAID görs flera hårddiskar till en logisk disk. Det finns olika sätt att göra detta på. Var och en av de metoder som sätter ihop hårddiskarna har vissa fördelar och nackdelar jämfört med att använda hårddiskarna som enskilda diskar, oberoende av varandra. De viktigaste skälen till att RAID används är följande:
- För att undvika att data går förlorade. Detta görs genom att ha flera kopior av uppgifterna.
- För att få mer lagringsutrymme genom att ha många mindre diskar.
- För att få större flexibilitet (diskar kan bytas ut eller läggas till medan systemet fortsätter att köras).
- För att få fram uppgifterna snabbare.
Det är inte möjligt att uppnå alla dessa mål samtidigt, så man måste göra val.
Det finns också några dåliga saker:
- Vissa val kan skydda mot att data går förlorade på grund av att en (eller flera) diskar har gått sönder. De skyddar dock inte mot att data raderas eller skrivs över.
- I vissa konfigurationer kan RAID tolerera att en eller flera diskar går sönder. När de trasiga diskarna har bytts ut måste data rekonstrueras. Beroende på konfigurationen och diskarnas storlek kan denna rekonstruktion ta lång tid.
- Vissa typer av fel gör det omöjligt att läsa uppgifterna.
Det mesta av arbetet med RAID bygger på en artikel från 1988.
Företag har använt RAID-system för att lagra data sedan tekniken infördes. RAID-system kan tillverkas på olika sätt. Sedan RAID-systemet upptäcktes har kostnaden för att bygga ett RAID-system minskat mycket. Av denna anledning har till och med vissa datorer och apparater som används i hemmet vissa RAID-funktioner. Sådana system kan till exempel användas för att lagra musik eller filmer.
Inledning och grundläggande begrepp
RAID organiserar flera fysiska diskar till en eller flera logiska enheter. Viktiga begrepp:
- Fysisk disk: den faktiska hårdvaruenheten (HDD eller SSD).
- Logisk disk: det operativsystemet ser — en kombination av en eller flera fysiska diskar.
- Striping: data delas upp i block (remsor) och sprids över flera diskar för bättre prestanda.
- Spegling: exakt kopia av data på två eller flera diskar (ger redundans).
- Paritet: extra information som gör det möjligt att återskapa data om en disk går sönder (används t.ex. i RAID 5 och 6).
- Hot spare: en extra disk som står redo att automatiskt ersätta en trasig disk vid fel.
- Stripe/chunk size: storleken på de datablock som skrivs till varje disk i en remsa; påverkar prestanda för olika arbetsbelastningar.
Hur läs- och skrivoperationer påverkas
Hur snabbt och säkert ett RAID ger åtkomst till data beror på konfigurationen:
- RAID 0 (striping) ökar läs- och skrivhastighet genom parallell bearbetning, men ger ingen redundans.
- RAID 1 (spegling) ger snabba läsningar (kan läsa från båda diskarna) och bra skydd mot avbrott, men halverar tillgänglig kapacitet.
- RAID med paritet (t.ex. RAID 5/6) kräver extra arbete vid skrivning (paritetsberäkning), men ger balans mellan kapacitet, prestanda och redundans.
Vanliga RAID-nivåer — vad de betyder och när man använder dem
Här är en översikt över de vanligaste nivåerna:
- RAID 0 (Striping)
- Minst: 2 diskar
- Fördelar: hög prestanda, full kapacitet (summa av diskarna).
- Nackdelar: ingen redundans — ett fel betyder dataförlust.
- Används för: temporära filer, cache, arbetsstationer där prestanda prioriteras över säkerhet.
- RAID 1 (Spegling)
- Minst: 2 diskar
- Fördelar: hög tillförlitlighet, enkel återställning.
- Nackdelar: 50 % lagringskostnad (två diskar ger kapacitet motsvarande en).
- Används för: systemdiskar, kritiska data där enkelhet och snabb återhämtning prioriteras.
- RAID 5 (Striping med distribuerad paritet)
- Minst: 3 diskar
- Fördelar: bra balans mellan kapacitet, prestanda och redundans (klarar en diskförlust).
- Nackdelar: skrivprestanda påverkas av paritetsberäkning; risk under återuppbyggnad om en läsbarhetsfel uppstår (UBE).
- Används för: fildelning, generella servrar med måttlig I/O.
- RAID 6
- Minst: 4 diskar
- Fördelar: dubbel paritet — klarar två samtidiga diskfel.
- Nackdelar: ännu större skrivkostnad än RAID 5; mer kapacitetsöverhead.
- Används för: stora diskar/arrayer där risken för ytterligare fel under återuppbyggnad är betydande.
- RAID 10 (1+0)
- Minst: 4 diskar (speglade par som stripas)
- Fördelar: kombination av prestanda och redundans; snabb återuppbyggnad eftersom endast en speglad partner behöver kopieras.
- Nackdelar: kräver många diskar; kapaciteten är halva summan.
- Används för: databaser och applikationer med höga krav på I/O och låg latens.
Icke-standardiserade och avancerade varianter
Det finns många proprietära eller specialanpassade varianter: RAID-DP, RAID-Z (ZFS), RAID 5E/6E, Intel Matrix RAID, och andra. De försöker förbättra prestanda, hantera hot spares, eller ge bättre skydd mot läsfel under återuppbyggnad.
Hur man skapar RAID — program- vs maskinvarulösningar
- Programvaru-RAID: hanteras av operativsystemet (t.ex. mdadm i Linux, Windows Storage Spaces). Fördelar: flexibel, billig, enkel att flytta mellan system. Nackdelar: belastar CPU något.
- Maskinvaru-RAID: dedikerad kontroller med egen processor och cache. Fördelar: ofta bättre prestanda, avancerade funktioner (BBU, cache). Nackdelar: dyrare, kan skapa låsning till specifik kontroller vid byte.
- Maskinvaruunderstödd (”fakeraid”): BIOS/UEFI assisterar men kräver drivrutin. Har nackdelar från både läger: kan vara begränsande och svårare att återställa utan samma hårdvara.
Maskinvarufel och reliabilitetsbegrepp
- MTTF/MTBF — medeltid till fel; hjälper att uppskatta sannolikhet för diskfel över tid.
- MTTR — medeltid till återhämtning; längre återuppbyggnadstid ökar risken för fler fel under processen.
- UBER (Unrecoverable Bit Error) — sannolikheten för ett läsbart fel vid stora diskar; relevans växer med diskstorlek och påverkar RAID 5 mer än RAID 6.
- Stora diskar = längre återuppbyggnadstider och högre sannolikhet för ytterligare fel — välj därför ofta dubbel paritet (RAID 6) eller spegling för stora volymer.
Problem, risker och vanliga fallgropar
- Återuppbyggnadstid: under återuppbyggnad är arrayen i ett sårbart läge — en andra diskförlust kan leda till dataförlust (beroende på nivån).
- Oåterkalleliga skrivfel: fel som orsakar korruption på flera diskar kan göra data otillgängliga.
- Skrivcache: förbättrar prestanda men kan orsaka dataförlust vid strömavbrott om det inte är batteri- eller flashbackat.
- Kompatibilitet: hårdvarukontrollers metadata kan vara proprietär — att flytta diskar mellan olika kontrollers kan vara problematiskt.
- Falska bra diskar: SMART kan visa OK trots att en disk snart fallerar — övervakning och reserve diskar rekommenderas.
- Atomicitet: vissa RAID-konfigurationer garanterar inte att flera samtidiga skrivningar är atomiska — det kan uppstå delvis skrivna data efter krascher.
Vad RAID kan och inte kan göra
- RAID kan:
- Skydda mot hårddiskfel (beroende på nivå).
- Öka läs-/skrivprestanda vid korrekt konfiguration.
- Göra system mer tillgängliga genom snabbare återhämtning vid diskbyte.
- RAID kan inte:
- Ersätta säkerhetskopior — det skyddar inte mot oavsiktlig radering, malware eller logisk korruption.
- Skydda mot fel i kontroller, brand eller stöld om inte replikerade säkerhetskopior finns offsite.
Praktiska rekommendationer och bästa praxis
- Ha alltid en separat backupstrategi utöver RAID (regelbundna, testade återställningar).
- Använd RAID 6 eller spegling för stora diskar/lagringspooler där lång återuppbyggnadstid är sannolik.
- Övervaka SMART-data och konfigurationsvarningar; byt ut diskar tidigt vid misstänkt fel.
- Använd hot spares där möjligt för minskad återhämtningstid.
- Välj lämplig stripe/chunk size baserat på arbetsbelastning: små storlekar för många små I/O, större för stora sekventiella filer.
- Undvik blandning av olika modeller/åldrar på diskar i samma array för att minska risken för samtidiga fel.
- Använd enterprise-drivrutiner eller diskar med TLER/Time-Limited Error Recovery för RAID-miljöer när det är möjligt.
- Aktivera eller använd kontroller med batteri- eller flash-backad skrivcache om du behöver write-back-prestanda utan risk för dataloss vid strömavbrott.
- Planera för återuppbyggnad: veta hur lång tid det tar och ha rutiner för övervakning under processen.
Exempel på användningsområden
- Arbetsstation som behöver hög prestanda men inte kritisk dataintegritet: RAID 0 (med regelbundna backuper).
- Filserver med balans mellan kapacitet och redundans: RAID 5 eller RAID 6 beroende på diskstorlek.
- Databas eller virtualiseringsvärd med högt IOPS-krav: RAID 10.
- Arkiv som kräver hög tillgänglighet: spegling + offsite-backup.
Avslutande kommentarer
RAID är ett kraftfullt verktyg för att kombinera diskar till större och mer tillförlitliga lagringsenheter. Val av RAID-nivå bör baseras på en avvägning mellan prestanda, kostnad och hur viktig datatillgängligheten är. Viktigast är att komma ihåg att RAID inte ersätter backups — korrekt backup- och återställningsrutiner är alltid nödvändiga.
Referenser och vidare läsning
- Den ursprungliga forskningsrapporten från 1988 ligger till grund för de flesta teorier kring RAID (ofta citerad i facklitteratur om RAID).
- Litteratur om operativsystemets RAID-stöd (t.ex. mdadm, ZFS, Windows Storage Spaces) ger praktiska instruktioner för implementation.
Inledning
Skillnaden mellan fysiska diskar och logiska diskar
En hårddisk är en del av en dator. Normala hårddiskar använder magnetism för att lagra information. När hårddiskar används är de tillgängliga för operativsystemet. I Microsoft Windows får varje hårddisk en enhetsbeteckning (som börjar med C:, A: eller B: är reserverade för diskettstationer). Unix- och Linuxliknande operativsystem har ett katalogträd med en enda rot. Detta innebär att de personer som använder datorerna ibland inte vet var informationen lagras (för att vara rättvis, många Windows-användare vet inte heller var deras data lagras).
Inom datateknik kallas hårddiskar (som är hårdvara och kan beröras) ibland för fysiska enheter eller fysiska diskar. Det som operativsystemet visar användaren kallas ibland logisk disk. En fysisk disk kan delas upp i olika sektioner som kallas diskpartitioner. Vanligtvis innehåller varje diskpartition ett filsystem. Operativsystemet visar varje partition som en logisk disk.
För användaren ser därför både konfigurationen med många fysiska diskar och konfigurationen med många logiska diskar likadan ut. Användaren kan inte avgöra om en "logisk disk" är samma sak som en fysisk disk eller om den bara är en del av disken. Storage Area Networks (SAN) ändrar helt och hållet detta synsätt. Allt som syns av ett SAN är ett antal logiska diskar.
Läsa och skriva data
I datorn organiseras data i form av bitar och bytes. I de flesta system består en byte av 8 bitar. Dataminnet använder elektricitet för att lagra data, medan hårddiskar använder magnetism. När data skrivs på en disk omvandlas därför den elektriska signalen till en magnetisk signal. När data läses från disken sker omvandlingen i andra riktningen: En elektrisk signal görs av polariteten hos ett magnetfält.
Vad är RAID?
En RAID-matris sammanfogar två eller flera hårddiskar så att de bildar en logisk disk. Det finns olika anledningar till varför detta görs. De vanligaste är:
- Stoppar dataförluster när en eller flera diskar i matrisen går sönder.
- Snabbare dataöverföringar.
- Du får möjlighet att byta diskar medan systemet fortsätter att köras.
- Sammanslagning av flera diskar för att få större lagringskapacitet; ibland används många billiga diskar i stället för en dyrare.
RAID görs med hjälp av särskild maskinvara eller programvara på datorn. De sammanfogade hårddiskarna ser då ut som en enda hårddisk för användaren. De flesta RAID-nivåer ökar redundansen. Detta innebär att de lagrar data oftare eller att de lagrar information om hur data ska rekonstrueras. Detta gör det möjligt för ett antal diskar att gå sönder utan att data går förlorade. När den trasiga disken byts ut kopieras eller återuppbyggs de data som den borde innehålla från de andra diskarna i systemet. Detta kan ta lång tid. Hur lång tid det tar beror på olika faktorer, till exempel arrayens storlek.
Varför använda RAID?
En av anledningarna till att många företag använder RAID är att data i matrisen helt enkelt kan användas. De som använder uppgifterna behöver inte vara medvetna om att de använder RAID överhuvudtaget. När ett fel inträffar och arrayen återhämtar sig kommer åtkomsten till data att vara långsammare. Tillgång till data under denna tid kommer också att sakta ner återhämtningsprocessen, men detta är fortfarande mycket snabbare än att inte kunna arbeta med data överhuvudtaget. Beroende på RAID-nivån kan det dock hända att disken inte går sönder medan den nya disken förbereds för användning. Om en disk går sönder vid den tidpunkten förlorar man alla data i matrisen.
De olika sätten att koppla ihop diskar kallas RAID-nivåer. En högre siffra för nivån är inte nödvändigtvis bättre. Olika RAID-nivåer har olika syften. Vissa RAID-nivåer kräver speciella diskar och speciella styrenheter.
Historia
1978 lade en man vid namn Norman Ken Ouchi, som arbetade på IBM, fram ett förslag som beskrev planerna för det som senare skulle bli RAID 5. I planerna beskrevs också något som liknade RAID 1, liksom skyddet av en del av RAID 4.
Arbetstagare vid Berkeley-universitetet hjälpte till att planera forskningen 1987. De försökte göra det möjligt för RAID-tekniken att känna igen två hårddiskar i stället för en. De fann att när RAID-tekniken hade två hårddiskar hade den mycket bättre lagringsmöjligheter än med endast en hårddisk. Den kraschade dock mycket oftare.
1988 skrev David Patterson, Garth Gibson och Randy Katz om de olika typerna av RAID (1 till 5) i artikeln "A Case for Redundant Arrays of Inexpensive Disks (RAID)". Artikeln var den första som kallade den nya tekniken för RAID och namnet blev officiellt.


Grundläggande begrepp som används i RAID-system
RAID bygger på några grundläggande idéer som beskrevs i artikeln "RAID: High-Performance, Reliable Secondary Storage" av Peter Chen med flera, som publicerades 1994.
Caching
Caching är en teknik som också används i RAID-system. Det finns olika typer av cacheminnen som används i RAID-system:
- Operativsystem
- RAID-kontroller
- Diskmatris för företag
I moderna system visas en skrivbegäran som utförd när data har skrivits till cacheminnet. Detta betyder inte att data har skrivits till disken. Begäranden från cacheminnet hanteras inte nödvändigtvis i samma ordning som de skrevs till cacheminnet. Detta gör det möjligt att vissa data ibland inte har skrivits till den berörda disken om systemet går sönder. Av denna anledning har många system en cache som backas upp av ett batteri.
Spegling: Mer än en kopia av data
När man talar om en spegel är detta en mycket enkel idé. I stället för att uppgifterna finns på ett enda ställe finns det flera kopior av uppgifterna. Dessa kopior finns vanligtvis på olika hårddiskar (eller diskpartitioner). Om det finns två kopior kan en av dem gå sönder utan att uppgifterna påverkas (eftersom de fortfarande finns kvar på den andra kopian). Spegling kan också ge ett uppsving vid läsning av data. Den kommer alltid att tas från den snabbaste disken som svarar. Att skriva data är dock långsammare eftersom alla diskar måste uppdateras.
Ränder: Delar av data finns på en annan disk.
Med striping delas data upp i olika delar. Dessa delar hamnar sedan på olika diskar (eller diskpartitioner). Detta innebär att det går snabbare att skriva data eftersom det kan göras parallellt. Detta innebär inte att det inte kommer att uppstå fel, eftersom varje datablock endast finns på en disk.
Felkorrigering och fel
Det är möjligt att beräkna olika typer av kontrollsummor. Vissa metoder för att beräkna kontrollsummor gör det möjligt att hitta ett fel. De flesta RAID-nivåer som använder redundans kan göra detta. Vissa metoder är svårare att göra, men de gör det möjligt att inte bara upptäcka felet utan också att åtgärda det.
Hot spares: använder fler diskar än vad som behövs
Många av de sätt som RAID stöder något som kallas hot spare. En hot spare är en tom disk som inte används i normal drift. När en disk går sönder kan data kopieras direkt till den heta reservdisken. På så sätt behöver den trasiga disken ersättas av en ny tom disk för att bli hot spare.
Stripe size och chunk size: Spridning av data på flera diskar.
RAID fungerar genom att data sprids över flera diskar. Två av de termer som ofta används i detta sammanhang är stripe size och chunk size.
Storleken på en bit är det minsta datablock som skrivs till en enskild disk i matrisen. Streckstorleken är storleken på ett datablock som sprids över alla diskar. Med fyra diskar och en bandstorlek på 64 kilobyte (kB) skrivs alltså 16 kB till varje disk. Blockstorleken i det här exemplet är därför 16 kB. Om strippstorleken är större innebär det en snabbare dataöverföringshastighet, men också en större maximal latenstid. I det här fallet är detta den tid som behövs för att få ett datablock.
Sätt ihop en skiva: JBOD, concatenation eller spanning
Många styrenheter (och även programvara) kan sätta ihop diskar på följande sätt: De tar den första skivan tills den slutar, sedan tar de den andra, och så vidare. På så sätt ser flera mindre diskar ut som en större. Detta är inte riktigt RAID, eftersom det inte finns någon redundans. Dessutom kan spanning kombinera diskar där RAID 0 inte kan göra något. I allmänhet kallas detta bara en massa diskar (JBOD).
Detta är en avlägsen släkting till RAID eftersom den logiska enheten består av olika fysiska enheter. Concatenation används ibland för att omvandla flera små enheter till en större användbar enhet. Detta kan inte göras med RAID 0. Med JBOD kan man till exempel kombinera enheter på 3 GB, 15 GB, 5,5 GB och 12 GB till en logisk enhet på 35,5 GB, som ofta är mer användbar än de enskilda enheterna.
I diagrammet till höger sammanfogas data från slutet av disk 0 (block A63) till början av disk 1 (block A64), slutet av disk 1 (block A91) till början av disk 2 (block A92). Om RAID 0 används skulle disk 0 och disk 2 avkortas till 28 block, storleken på den minsta disken i matrisen (disk 1), vilket ger en total storlek på 84 block.
Vissa RAID-kontrollanter använder JBOD för att tala om att arbeta på enheter utan RAID-funktioner. Varje enhet visas separat i operativsystemet. JBOD är inte samma sak som concatenation.
Många Linuxsystem använder uttrycken "linjärt läge" eller "append-läge". I Mac OS X 10.4 - som kallas "Concatenated Disk Set" - har användaren inte kvar några användbara data på de återstående enheterna om en enhet går sönder i en concatenated disk set, även om diskarna i övrigt fungerar som beskrivet ovan.
Sammanfogning är en av användningsområdena för Logical Volume Manager i Linux. Den kan användas för att skapa virtuella enheter.
Klon av en enhet
De flesta moderna hårddiskar har en standard som kallas S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology). SMART gör det möjligt att övervaka vissa saker på en hårddisk. Vissa styrenheter gör det möjligt att byta ut en enskild hårddisk redan innan den går sönder, t.ex. för att S.M.A.R.T eller ett annat skivtest rapporterar för många korrigerbara fel. För att göra detta kopierar styrenheten alla data till en reservdisk. Därefter kan disken ersättas med en annan (som helt enkelt blir den nya hot spare-disken).
Olika inställningar
Hur diskarna är konfigurerade och hur de använder ovanstående tekniker påverkar systemets prestanda och tillförlitlighet. När fler diskar används är det mer sannolikt att en av diskarna går sönder. På grund av detta måste mekanismer byggas för att kunna hitta och åtgärda fel. Detta gör hela systemet mer tillförlitligt eftersom det kan överleva och reparera felet.

Grunderna: enkla RAID-nivåer
RAID-nivåer som används allmänt
RAID 0 "strippning"
RAID 0 är inte riktigt RAID eftersom den inte är redundant. Med RAID 0 sätts diskarna helt enkelt ihop till en stor disk. Detta kallas "striping". När en disk går sönder går hela matrisen sönder. Därför används RAID 0 sällan för viktiga data, men det kan gå snabbare att läsa och skriva data från disken med striping eftersom varje disk läser en del av filen samtidigt.
Med RAID 0 placeras diskblock som kommer efter varandra vanligtvis på olika diskar. Därför bör alla diskar som används av en RAID 0 vara lika stora.
RAID 0 används ofta för Swapspace i Linux eller Unix-liknande operativsystem.
RAID 1 "spegling"
Med RAID 1 sätts två diskar ihop. Båda innehåller samma data och den ena "speglar" den andra. Detta är en enkel och snabb konfiguration, oavsett om den genomförs med en hårdvarukontroller eller med programvara.
RAID 5 "Striping med distribuerad paritet"
RAID-nivå 5 är det som förmodligen används mest. Minst tre hårddiskar behövs för att bygga en RAID 5 lagringsarray. Varje datablock lagras på tre olika ställen. Två av dessa platser lagrar blocket som det är, den tredje lagrar en kontrollsumma. Denna kontrollsumma är ett specialfall av en Reed-Solomon-kod som endast använder bitvis addition. Vanligtvis beräknas den med hjälp av XOR-metoden. Eftersom denna metod är symmetrisk kan ett förlorat datablock återskapas från det andra datablocket och kontrollsumman. För varje block finns paritetsblocket, som innehåller kontrollsumman, på en annan disk. Detta görs för att öka redundansen. Alla diskar kan gå sönder. Totalt sett kommer det att finnas en disk som innehåller kontrollsummorna, så den totala användbara kapaciteten kommer att vara den för alla diskar utom en. Storleken på den resulterande logiska disken kommer att vara storleken på alla diskar tillsammans, utom en disk som innehåller paritetsinformation.
Detta är naturligtvis långsammare än RAID-nivå 1, eftersom alla diskar måste läsas vid varje skrivning för att beräkna och uppdatera paritetsinformationen. Läsprestanda för RAID 5 är nästan lika bra som RAID 0 för samma antal diskar. Med undantag för paritetsblocken följer fördelningen av data över diskarna samma mönster som RAID 0. Anledningen till att RAID 5 är något långsammare är att diskarna måste hoppa över paritetsblocken.
En RAID 5 med en trasig disk fortsätter att fungera. Den är i försämrat läge. En nedbruten RAID 5 kan vara mycket långsam. Av denna anledning läggs ofta en extra disk till. Detta kallas hot spare-disk. Om en disk går sönder kan data direkt återskapas på den extra disken. RAID 5 kan också göras i programvara ganska enkelt.
På grund av prestandaproblem med misslyckade RAID 5-matriser har vissa databasexperter bildat en grupp som kallas BAARF (Battle Against Any Raid Five).
Om systemet går sönder medan det pågår skrivningar kan pariteten i ett band bli inkonsekvent med data. Om detta inte repareras innan en disk eller ett block går sönder kan dataförlust uppstå. En felaktig paritet kommer att användas för att rekonstruera det saknade blocket i det aktuella remsan. Detta problem kallas ibland för "skrivhålet". Batteribaserade cacheminnen och liknande tekniker används ofta för att minska risken för att detta skall inträffa.
Bilder
· 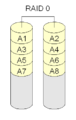
RAID 0 placerar helt enkelt de olika blocken på olika diskar. Det finns ingen redundans.
· 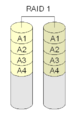
Med Raid 1 finns varje block på båda diskarna.
· 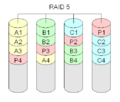
RAID 5 beräknar särskilda kontrollsummor för data. Både blocken med kontrollsumman och blocken med data fördelas på alla diskar.
RAID-nivåer som används mindre
RAID 2
Detta användes för mycket stora datorer. Speciellt dyra diskar och en speciell styrenhet behövs för att använda RAID nivå 2. Data distribueras på bitnivå (alla andra nivåer använder åtgärder på byte-nivå). Särskilda beräkningar görs. Data delas upp i statiska sekvenser av bitar. 8 databitar och 2 paritetsbitar sätts samman. Därefter beräknas en Hamming-kod. Fragmenten av Hammingkoden fördelas sedan på de olika diskarna.
RAID 2 är den enda RAID-nivå som kan reparera fel, de andra RAID-nivåerna kan bara upptäcka dem. När de upptäcker att den information som behövs inte är meningsfull, bygger de helt enkelt om den. Detta görs med hjälp av beräkningar och med hjälp av information på de andra diskarna. Om den informationen saknas eller är felaktig kan de inte göra mycket. Eftersom RAID 2 använder Hammingkoder kan den ta reda på vilken del av informationen som är felaktig och korrigera endast den delen.
RAID 2 behöver minst 10 diskar för att fungera. På grund av dess komplexitet och behovet av mycket dyr och speciell hårdvara används RAID 2 inte längre särskilt ofta.
RAID 3 "Striping med dedikerad paritet"
Raid Level 3 är ungefär som RAID Level 0. En extra disk läggs till för att lagra paritetsinformation. Detta görs genom bitvis addition av värdet för ett block på de andra diskarna. Paritetsinformationen lagras på en separat (dedikerad) disk. Detta är inte bra, eftersom paritetsinformationen går förlorad om paritetsdisken går sönder.
RAID-nivå 3 används vanligtvis med minst tre diskar. En uppsättning med två diskar är identisk med en RAID-nivå 0.
RAID 4 "Striping med dedikerad paritet"
Detta är mycket likt RAID 3, förutom att paritetsinformationen beräknas över större block och inte över enskilda bytes. Detta liknar RAID 5. Minst tre diskar behövs för en RAID 4-matris.
RAID 6
RAID-nivå 6 var inte en ursprunglig RAID-nivå. Den lägger till ett extra paritetsblock till en RAID 5-matris. Den behöver minst fyra diskar (två diskar för kapaciteten, två diskar för redundans). RAID 5 kan ses som ett specialfall av en Reed-Solomon-kod. RAID 5 är dock ett specialfall, eftersom den endast behöver addition i Galoisfältet GF(2). Detta är lätt att göra med XORs. RAID 6 utökar dessa beräkningar. Det är inte längre ett specialfall och alla beräkningar måste göras. Med RAID 6 används en extra kontrollsumma (kallad polynom), vanligen av GF (28). Med detta tillvägagångssätt är det möjligt att skydda sig mot ett obegränsat antal trasiga diskar. RAID 6 är för det fall då man använder två kontrollsummor för att skydda mot förlust av två diskar.
Precis som med RAID 5 finns paritet och data på olika diskar för varje block. De två paritetsblocken finns också på olika diskar.
Det finns olika sätt att göra RAID 6. De skiljer sig åt när det gäller skrivprestanda och hur mycket beräkningar som behövs. Att kunna göra snabbare skrivningar innebär vanligtvis att det krävs fler beräkningar.
RAID 6 är långsammare än RAID 5, men det gör att RAID:en kan fortsätta även om två diskar är trasiga. RAID 6 blir alltmer populärt eftersom det gör det möjligt att bygga upp en matris igen efter ett fel på en enda disk även om en av de återstående diskarna har en eller flera felaktiga sektorer.
Bilder
· 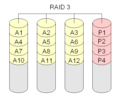
RAID 3 är ungefär som RAID-nivå 0. En extra disk läggs till som innehåller en kontrollsumma för varje datablock.
· 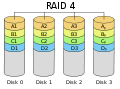
RAID 4 liknar RAID-nivå 3, men beräknar paritet över större block av data.
· 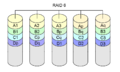
RAID 6 liknar RAID 5, men beräknar två olika kontrollsummor. Detta gör att två diskar kan gå sönder utan att data går förlorade.
Icke-standardiserade RAID-nivåer
Dubbel paritet / Diagonal paritet
RAID 6 använder två paritetsblock. Dessa beräknas på ett särskilt sätt över ett polynom. Dubbel paritets-RAID (även kallad diagonal paritets-RAID) använder ett annat polynom för vart och ett av dessa paritetsblock. Den branschorganisation som definierat RAID har nyligen sagt att RAID med dubbel paritet är en annan form av RAID 6.
RAID-DP
RAID-DP är ett annat sätt att ha dubbel paritet.
RAID 1.5
RAID 1.5 (inte att förväxla med RAID 15, som är annorlunda) är en proprietär RAID-implementering. Liksom RAID 1 använder den endast två diskar, men den gör både striping och spegling (liknande RAID 10). Det mesta görs i maskinvara.
RAID 5E, RAID 5EE och RAID 6E
RAID 5E, RAID 5EE och RAID 6E (med tillägget E för Enhanced) hänvisar i allmänhet till olika typer av RAID 5 eller RAID 6 med en hot spare. I dessa tillämpningar är reservdriften inte en fysisk enhet. Den finns snarare i form av ledigt utrymme på diskarna. Detta ökar prestandan, men innebär att en hot spare-disk inte kan delas mellan olika matriser. Systemet infördes av IBM ServeRAID omkring 2001.
RAID 7
Detta är en egenutvecklad implementering. Den lägger till caching till en RAID 3- eller RAID 4-array.
Intel Matrix RAID
Vissa Intel-huvudkort har RAID-chip som har denna funktion. Det använder två eller tre diskar och delar sedan upp dem lika för att bilda en kombination av RAID 0-, RAID 1-, RAID 5- eller RAID 1+0-nivåer.
Linux MD RAID-drivrutin
Detta är namnet på drivrutinen som gör det möjligt att använda mjukvaru-RAID i Linux. Förutom de normala RAID-nivåerna 0-6 har den också en RAID 10-implementering. Sedan Kernel 2.6.9 är RAID 10 en enda nivå. Genomförandet har några icke-standardiserade funktioner.
RAID Z
Sun har implementerat ett filsystem som kallas ZFS. Detta filsystem är optimerat för att hantera stora mängder data. Det innehåller en logisk volymhanterare. Det innehåller också en funktion som kallas RAID-Z. Det undviker det problem som kallas RAID 5 write hole eftersom det har en policy för kopiering vid skrivning: Den skriver inte över data direkt utan skriver nya data på en ny plats på disken. När skrivningen lyckades raderas de gamla uppgifterna. Den undviker behovet av läs-, ändrings- och skrivoperationer för små skrivningar, eftersom den bara skriver hela stråk. Små block speglas i stället för att paritetsskyddas, vilket är möjligt eftersom filsystemet känner till hur lagret är organiserat. Det kan därför allokera extra utrymme vid behov. Det finns också RAID-Z2 som använder två former av paritet för att uppnå resultat som liknar RAID 6: förmågan att överleva upp till två diskfel utan att förlora data.
Bilder
· 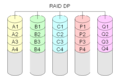
Diagram över en RAID DP-installation (Double Parity).
· 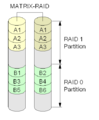
En Matrix RAID-installation.
Sammanfogning av RAID-nivåer
Med RAID kan olika diskar sättas ihop till en logisk disk.Användaren ser bara den logiska disken. Var och en av de RAID-nivåer som nämns ovan har bra och dåliga sidor. Men RAID kan också fungera med logiska diskar. På så sätt kan en av RAID-nivåerna ovan användas med en uppsättning logiska diskar. Många noterar det genom att skriva ihop siffrorna. Ibland skriver de ett "+" eller ett "&" emellan. Vanliga kombinationer (med två nivåer) är följande:
- RAID 0+1: Två eller flera RAID 0-matriser kombineras till en RAID 1-matris; detta kallas Mirror of stripes.
- RAID 1+0: Samma som RAID 0+1, men RAID-nivåerna är omvända; Stripe of Mirrors. Detta gör diskfel mer sällsynt än RAID 0+1 ovan.
- RAID 5+0: Stripe flera RAID 5:or med en RAID 0. En disk i varje RAID 5 kan gå sönder, men RAID 5 blir den enda felpunkten; om en annan disk i den matrisen går sönder går alla data i matrisen förlorade.
- RAID 5+1: Spegla en uppsättning RAID 5: I en situation där RAID består av sex diskar kan tre diskar gå sönder (utan att data går förlorade).
- RAID 6+0: Stripe flera RAID 6-matriser över en RAID 0. Två diskar i varje RAID 6 kan gå sönder utan att data går förlorade.
Med sex diskar på 300 GB vardera, med en total kapacitet på 1,8 TB, är det möjligt att skapa en RAID 5 med 1,5 TB användbart utrymme. I den matrisen kan en disk gå sönder utan att data går förlorade. Med RAID 50 minskas utrymmet till 1,2 TB, men en disk i varje RAID 5 kan gå sönder, och dessutom ökar prestandan märkbart. RAID 51 minskar det användbara utrymmet till 900 GB, men tillåter att tre diskar kan gå sönder.
· 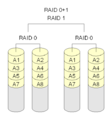
RAID 0+1: Flera RAID 0-matriser kombineras med en RAID 1-matris.
· 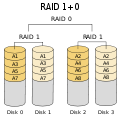
RAID 1+0: Robustare än RAID 0+1; klarar av fel på flera enheter, så länge ingen av de enheter som bildar en spegel går sönder.
· 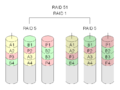
RAID 5+1: Alla tre enheter i detta system kan gå sönder utan att data går förlorade.
Skapa en RAID
Det finns olika sätt att skapa en RAID. Det kan antingen göras med programvara eller med hårdvara.
Programvaru-RAID
En RAID kan skapas med programvara på två olika sätt. I fallet Software RAID är diskarna anslutna som vanliga hårddiskar. Det är datorn som får RAID att fungera. Detta innebär att för varje åtkomst måste processorn också göra beräkningarna för RAID:en. Beräkningarna för RAID 0 eller RAID 1 är enkla. Beräkningarna för RAID 5, RAID 6 eller en av de kombinerade RAID-nivåerna kan dock vara mycket arbete. I en mjukvaru-RAID kan det vara svårt att automatiskt starta upp från en matris som har misslyckats. Slutligen beror det sätt på vilket RAID görs i programvara på det operativsystem som används; det är i allmänhet inte möjligt att bygga om en RAID-matris i programvara med ett annat operativsystem. Operativsystemen använder vanligtvis hårddiskpartitioner snarare än hela hårddiskar för att skapa RAID-matriser.
Maskinvaru-RAID
En RAID kan också skapas med hårdvara. I detta fall används en speciell diskcontroller som döljer för operativsystemet och användaren att den gör RAID. Beräkningarna av kontrollsumminformationen och andra RAID-relaterade beräkningar görs på ett särskilt mikrochip i denna styrenhet. Detta gör RAID oberoende av operativsystemet. Operativsystemet kommer inte att se RAID, utan en enda disk. Olika tillverkare använder RAID på olika sätt. Detta innebär att en RAID som byggs med en RAID-kontroller inte kan byggas om av en annan RAID-kontroller från en annan tillverkare. RAID-kontroller för hårdvara är ofta dyra att köpa.
Maskinvaruunderstödd RAID
Detta är en blandning mellan hårdvaru-RAID och mjukvaru-RAID. Vid hårdvaruassisterad RAID används ett särskilt kontrollchip (som hårdvaru-RAID), men detta chip kan inte utföra många operationer. Det är bara aktivt när systemet startas; så snart operativsystemet är helt laddat är denna konfiguration som mjukvaru-RAID. Vissa moderkort har RAID-funktioner för de anslutna diskarna; oftast utförs dessa RAID-funktioner som hårdvaruassisterad RAID. Detta innebär att det behövs särskild programvara för att kunna använda dessa RAID-funktioner och för att kunna återställa en trasig disk.
Olika termer som rör maskinvarufel
Det finns olika termer som används när man talar om maskinvarufel:
Antal misslyckanden
Felprocenten är hur ofta ett system misslyckas. Medeltiden till fel (MTTF) eller medeltiden mellan fel (MTBF) för ett RAID-system är densamma som för dess komponenter. Ett RAID-system kan trots allt inte skydda mot fel på de enskilda hårddiskarna. De mer komplicerade typerna av RAID (allt annat än "striping" eller "concatenation") kan dock hjälpa till att hålla data intakta även om en enskild hårddisk går sönder.
Medeltid till dataförlust
Medeltid till dataförlust (MTTDL) anger den genomsnittliga tiden innan en dataförlust inträffar i en viss matris. Den genomsnittliga tiden till dataförlust för en viss RAID kan vara högre eller lägre än för dess hårddiskar. Detta beror på vilken typ av RAID som används.
Medeltid till återhämtning
Arrayer med redundans kan återhämta sig från vissa fel. Medeltiden för återhämtning visar hur lång tid det tar innan en felande matris är tillbaka i sitt normala tillstånd. Detta inkluderar både tiden för att ersätta en trasig diskmekanism och tiden för att bygga upp matrisen igen (dvs. replikera data för redundans).
Oåterställbar bitfelfrekvens
UBE (unrecoverable bit error rate) anger hur länge en diskettstation inte kan återställa data efter att ha använt CRC-koder (cyclic redundancy check) och flera försök.
Problem med RAID
Det finns också vissa problem med idéerna eller tekniken bakom RAID:
Lägga till diskar vid en senare tidpunkt
Vissa RAID-nivåer gör det möjligt att utöka matrisen genom att helt enkelt lägga till hårddiskar vid en senare tidpunkt. Information, t.ex. paritetsblock, är ofta utspridd på flera diskar. Om en disk läggs till i matrisen innebär det att en omorganisation blir nödvändig. En sådan omorganisation är som en ombyggnad av matrisen och kan ta lång tid. När detta görs kanske det extra utrymmet inte är tillgängligt ännu, eftersom både filsystemet på matrisen och operativsystemet måste informeras om det. Vissa filsystem har inte stöd för att växa efter att de har skapats. I sådana fall måste alla data säkerhetskopieras, matrisen måste skapas på nytt med den nya layouten och data måste återställas på den.
Ett annat alternativ för att lägga till lagringsutrymme är att skapa en ny matris och låta en logisk volymhanterare hantera situationen. Detta gör det möjligt att utöka nästan alla RAID-system, även RAID1 (som i sig självt är begränsat till två diskar).
Kopplade misslyckanden
Felkorrigeringsmekanismen i RAID förutsätter att fel på enheterna är oberoende av varandra. Det är möjligt att beräkna hur ofta en del av utrustningen kan gå sönder och att ordna matrisen så att dataförluster blir mycket osannolika.
I praktiken köptes enheterna dock ofta tillsammans. De är ungefär lika gamla och har använts på samma sätt (så kallat slitage). Många enheter går sönder på grund av mekaniska problem. Ju äldre en enhet är, desto mer slitna är dess mekaniska delar. Mekaniska delar som är gamla har större sannolikhet att gå sönder än de som är yngre. Detta innebär att fel på enheter inte längre är statistiskt oberoende. I praktiken finns det en chans att en andra disk också går sönder innan den första har återställts. Detta innebär att dataförlusterna i praktiken kan inträffa i betydande omfattning.
Atomicitet
Ett annat problem som också uppstår med RAID-system är att programmen förväntar sig vad som kallas atomicitet: Antingen skrivs alla data eller så skrivs inga data. Att skriva data kallas för en transaktion.
I RAID-matriser skrivs de nya uppgifterna vanligtvis på den plats där de gamla uppgifterna fanns. Detta har blivit känt som uppdatering på plats. Jim Gray, en databasforskare, skrev en artikel 1981 där han beskrev detta problem.
Mycket få lagringssystem tillåter atomisk skrivsemantik. När ett objekt skrivs till disken skriver en RAID-lagringsenhet vanligtvis alla kopior av objektet parallellt. Mycket ofta finns det bara en processor som ansvarar för att skriva data. I ett sådant fall kommer skrivningarna av data till de olika enheterna att överlappa varandra. Detta kallas för överlappande skrivning eller förskjuten skrivning. Ett fel som inträffar under skrivprocessen kan därför göra att de redundanta kopiorna hamnar i olika tillstånd. Vad värre är, det kan leda till att kopiorna varken befinner sig i det gamla eller det nya tillståndet. Loggning bygger dock på att originaldata antingen befinner sig i det gamla eller det nya tillståndet. Detta gör det möjligt att backa ut den logiska ändringen, men få lagringssystem tillhandahåller en atomär skrivsemantik på en RAID-disk.
Om du använder en batteridriven skrivcache kan du lösa det här problemet, men bara om det är ett strömavbrott.
Transaktionsstöd finns inte i alla RAID-kontroller för maskinvara. Därför ingår det i många operativsystem för att skydda mot dataförlust vid avbruten skrivning. Novell Netware, med början i version 3.x, innehöll ett system för transaktionsspårning. Microsoft införde transaktionsspårning via journalfunktionen i NTFS. NetApp WAFL-filsystemet löser det genom att aldrig uppdatera data på plats, liksom ZFS.
Uppgifter som inte kan återställas
Vissa sektorer på hårddisken kan ha blivit oläsbara på grund av ett misstag. Vissa RAID-implementeringar kan hantera denna situation genom att flytta data till en annan plats och markera sektorn på disken som dålig. Detta sker ungefär 1 bit på 1015 i diskdiskar i företagsklass och 1 bit på 1014 i vanliga diskdiskar. Diskkapaciteten ökar stadigt. Detta kan innebära att en RAID ibland inte kan byggas om, eftersom ett sådant fel upptäcks när matrisen byggs om efter ett diskfel. Vissa tekniker, t.ex. RAID 6, försöker lösa detta problem, men de lider av ett mycket högt skrivstraff, med andra ord blir det mycket långsamt att skriva data.
Tillförlitlighet för skrivcache
Disksystemet kan bekräfta skrivoperationen så snart data finns i cacheminnet. Det behöver inte vänta tills data har skrivits fysiskt. Ett strömavbrott kan dock innebära en betydande dataförlust för alla data som står i kö i en sådan cache.
Med hårdvaru-RAID kan ett batteri användas för att skydda denna cache. Detta löser ofta problemet. När strömmen bryts kan styrenheten skriva färdigt cachen när strömmen är tillbaka. Den här lösningen kan dock fortfarande misslyckas: batteriet kan ha slits ut, strömmen kan ha varit avstängd för länge, diskarna kan flyttas till en annan styrenhet, själva styrenheten kan gå sönder. Vissa system kan göra regelbundna batterikontroller, men dessa använder själva batteriet och lämnar det i ett tillstånd där det inte är fullt laddat.
Utrustningens kompatibilitet
Diskformaten på olika RAID-kontroller är inte nödvändigtvis kompatibla. Därför är det kanske inte möjligt att läsa en RAID-matris på olika maskinvara. Om det uppstår ett fel på maskinvaran som inte är en disk kan det därför vara nödvändigt att använda identisk maskinvara eller en backup för att återställa data.
Vad RAID kan och inte kan göra
Den här guiden är hämtad från en tråd i ett RAID-relaterat forum. Detta gjordes för att hjälpa till att visa på för- och nackdelar med att välja RAID. Den riktar sig till personer som vill välja RAID för att antingen öka prestandan eller för redundans. Den innehåller länkar till andra trådar i dess forum som innehåller användargenererade anekdotiska recensioner av deras RAID-erfarenheter.
Vad RAID kan göra
- RAID kan skydda drifttiden. RAID-nivåerna 1, 0+1/10, 5 och 6 (och deras varianter som 50 och 51) kompenserar för mekaniska hårddiskfel. Även efter att disken har gått sönder kan data i matrisen fortfarande användas. Istället för en tidskrävande återställning från band, DVD eller andra långsamma säkerhetskopieringsmedier kan data med hjälp av RAID återställas till en ersättningsdisk från de andra medlemmarna i matrisen. Under denna återställningsprocess är den tillgänglig för användare i ett försämrat tillstånd. Detta är mycket viktigt för företag, eftersom driftstopp snabbt leder till förlorad intjäningsförmåga. För hemmabrukare kan det skydda drifttiden för stora medielagringsenheter, som skulle kräva tidskrävande återställning från dussintals DVD:er eller en hel del band om en disk som inte skyddas av redundans skulle gå sönder.
- RAID kan öka prestandan i vissa tillämpningar. RAID-nivåerna 0, 5 och 6 använder alla striping. Detta gör det möjligt för flera spindlar att öka överföringshastigheten för linjära överföringar. Applikationer av arbetsstationstyp arbetar ofta med stora filer. De har stor nytta av striping av diskar. Exempel på sådana tillämpningar är de som använder video- eller ljudfiler. Denna genomströmning är också användbar vid säkerhetskopiering från disk till disk. RAID 1 liksom andra stripingbaserade RAID-nivåer kan förbättra prestandan för åtkomstmönster med många samtidiga slumpmässiga åtkomster, t.ex. de som används av en databas med flera användare.
Vad RAID inte kan göra
- RAID kan inte skydda data i matrisen. En RAID-array har ett filsystem. Detta skapar en enda felpunkt. Det finns många andra saker som kan hända med detta filsystem än fysiska diskfel. RAID kan inte skydda sig mot dessa källor till dataförlust. RAID kan inte hindra ett virus från att förstöra data. RAID förhindrar inte korruption. RAID kan inte rädda data när en användare ändrar dem eller raderar dem av misstag. RAID skyddar inte data från maskinvarufel i någon annan komponent än fysiska diskar. RAID skyddar inte data från naturkatastrofer eller katastrofer orsakade av människan, t.ex. bränder och översvämningar. För att skydda data måste de säkerhetskopieras på flyttbara medier, t.ex. DVD, band eller en extern hårddisk. Säkerhetskopian måste förvaras på en annan plats. Enbart RAID kan inte förhindra att en katastrof, när (inte om) den inträffar, leder till dataförlust. Katastrofer kan inte förhindras, men med hjälp av säkerhetskopior kan man förhindra dataförluster.
- RAID kan inte förenkla katastrofåterställning. När en enda disk används kan den användas av de flesta operativsystem eftersom de har en gemensam enhetsdrivrutin. De flesta RAID-kontroller behöver dock särskilda drivrutiner. Återställningsverktyg som fungerar med enstaka diskar på generiska styrenheter kräver särskilda drivrutiner för att få tillgång till data i RAID-matriser. Om dessa återställningsverktyg är dåligt kodade och inte tillåter ytterligare drivrutiner, kommer en RAID-array förmodligen att vara otillgänglig för återställningsverktyget.
- RAID kan inte ge en prestandaförbättring i alla tillämpningar. Detta gäller särskilt för typiska användare av skrivbordstillämpningar och spelare. För de flesta skrivbordsprogram och spel är buffertstrategin och diskarnas sökprestanda viktigare än den råa genomströmningen. En ökning av den råa överföringshastigheten ger små vinster för sådana användare, eftersom de flesta filer som de får tillgång till är mycket små ändå. Striping av diskar med RAID 0 ökar den linjära överföringsprestandan, inte buffert- och sökprestandan. Därför ger disk striping med RAID 0 liten eller ingen prestandaökning i de flesta skrivbordsprogram och spel, även om det finns undantag. För skrivbordsanvändare och spelare med hög prestanda som mål är det bättre att köpa en snabbare, större och dyrare enskild disk än att köra två långsammare/mindre diskar i RAID 0. Även om man kör de senaste, bästa och största diskarna i RAID-0 är det osannolikt att prestandan ökar med mer än 10 %, och prestandan kan sjunka i vissa åtkomstmönster, särskilt i spel.
- Det är svårt att flytta RAID till ett nytt system. Med en enskild disk är det relativt enkelt att flytta disken till ett nytt system. Den kan helt enkelt anslutas till det nya systemet, om det har samma gränssnitt tillgängligt. Detta är dock inte lika enkelt med en RAID-array. Det finns en viss typ av metadata som säger hur RAID är konfigurerad. Ett RAID BIOS måste kunna läsa dessa metadata så att det framgångsrikt kan bygga upp matrisen och göra den tillgänglig för ett operativsystem. Eftersom tillverkarna av RAID-kontroller använder olika format för sina metadata (till och med kontrollörer av olika familjer från samma tillverkare kan använda inkompatibla metadataformat) är det nästan omöjligt att flytta en RAID-matris till en annan kontrollör. När man flyttar en RAID-matris till ett nytt system bör man planera för att också flytta kontrollern. Med populariteten av moderkortintegrerade RAID-kontroller är detta extremt svårt. I allmänhet är det möjligt att flytta RAID-arraymedlemmar och styrenheter tillsammans. Mjukvaru-RAID i Linux och Windows Server Products kan också kringgå denna begränsning, men mjukvaru-RAID har andra begränsningar (främst prestandarelaterade).
Exempel
De RAID-nivåer som oftast används är RAID 0, RAID 1 och RAID 5. Antag att det finns en installation med tre diskar, med tre identiska diskar på 1 TB vardera, och att sannolikheten för att en disk ska gå sönder under en viss tidsperiod är 1 %.
| RAID-nivå | Användbar kapacitet | Sannolikhet för misslyckande anges i procent | Sannolikhet för misslyckande 1 i ... fall misslyckas |
| 0 | 3 TB | 2,9701% | 34 |
| 1 | 1 TB | 0,0001% | 1 miljon euro |
| 5 | 2 TB | 0,0298% | 3356 |
Författare
AlegsaOnline.com RAID – komplett guide: definition, nivåer, fördelar och risker Leandro Alegsa
URL: https://sv.alegsaonline.com/art/80859
Källor
- www-2.cs.cmu.edu : ""A Case for Redundant Arrays of Inexpensive Disks" - Patterson, Gibson, Katz"
- thomason.org : "RAID: High-Performance, Reliable Secondary Storage"
- baarf.com : "BAARF - Battle Against Any Raid Five"
- media.netapp.com : "RAID-DP™: Network Appliance™ implementation of RAID Double Parity for data protection, a high speed implementation of RAID 6"
- nasi.com : "IBM X-Architecture Technology 2001:A design blueprint for Intel processor-based servers"
- pcguide.com : "RAID Level 7"
- cgi.cse.unsw.edu.au : "Linux RAID 10 driver"
- linux-raid.osdl.org : "Main Page - Linux-raid"
- blogs.sun.com : "RAID-Z : Jeff Bonwick's Blog"
- blogs.sun.com : "Adam Leventhal's Weblog"
- research.microsoft.com : "Empirical Measurements of Disk Failure Rates and Error Rates"
- usenix.org : "Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?"
- research.microsoft.com : "The Transaction Concept: Virtues and Limitations (Invited Paper)¦format=pdf"
- informatik.uni-trier.de : "VLDB 1981"
- arxiv.org : "Empirical Measurements of Disk Failure Rates and Error Rates"