Zipfs lag: rang–frekvensfördelning i språk och andra system
Zipfs lag beskriver en empirisk rang–frekvensrelation där frekvensen oftast är omvänt proportionell mot ranken. Tillämpningar finns i språk, stadsskalor och olika kraftlagar.
Översikt
Zipfs lag är en empirisk lag som beskriver hur förekomsten av element i stora uppsättningar ofta förhåller sig till deras plats i en rangordning. Lagen är uppkallad efter lingvisten George Kingsley Zipf, som populariserade observationen under 1930– och 1940-talen. Fenomenet iakttogs dock tidigare i andra sammanhang, bland annat i studier av staders storlekar.
Bildgalleri
3 Bilder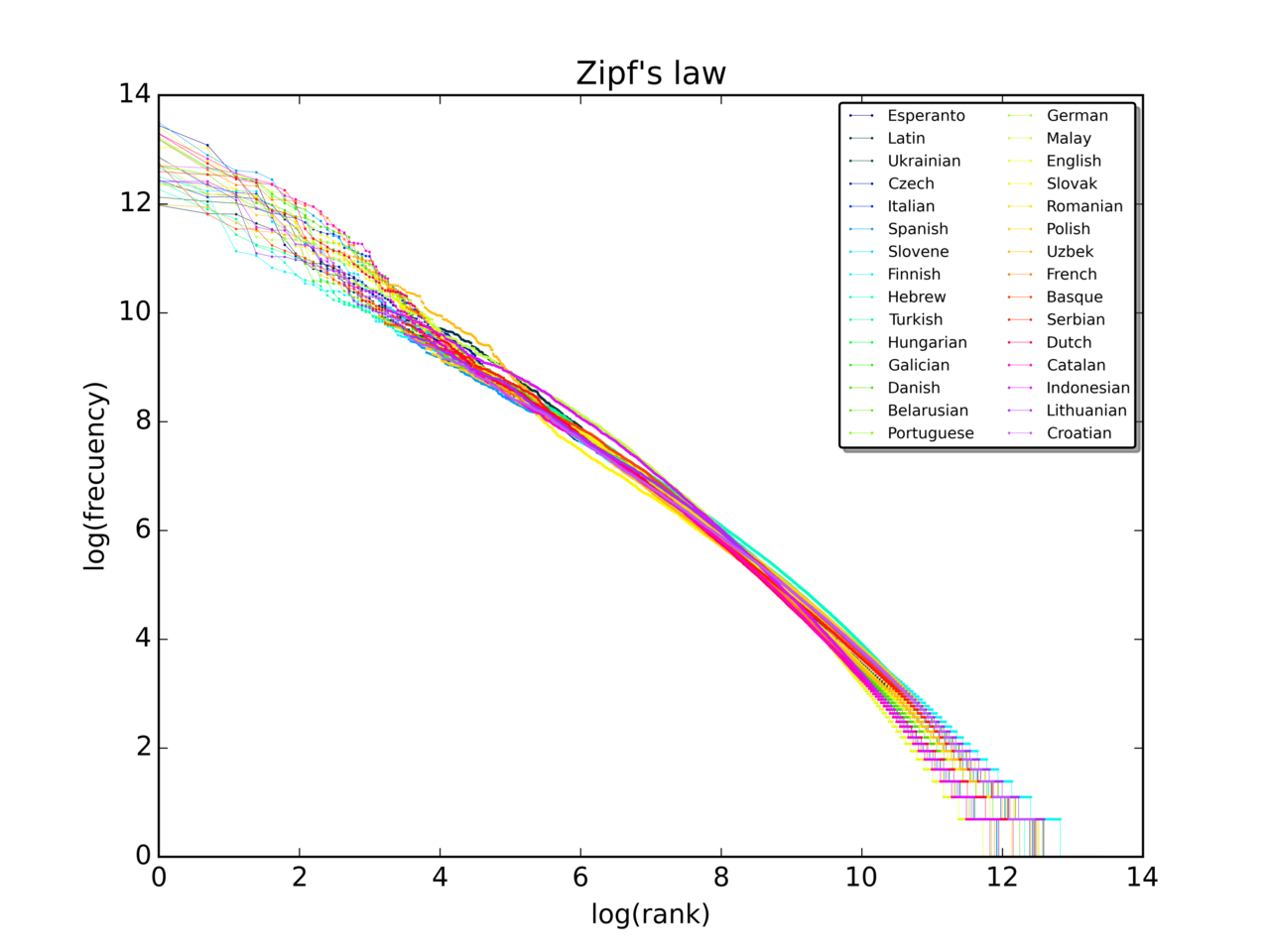


Vad lagen säger
Den enklaste formen av Zipfs lag uttrycks som att frekvensen f_r för det element som har rang r är ungefär proportionell mot 1/r. I praktiken skrivs detta ofta som f_r \u221D 1/r eller mer allmänt f_r = C / r^s, där konstanten s ligger nära 1 i många empiriska fall. Denna förklaring avser rang i en frekvenstabell och kan formellt härledas eller testas med hjälp av matematisk och statistisk analys.
Exempel och tillämpningar
Zipfs lag upptäcks inte bara i språk. Några vanliga exempel är:
- Ord i textkorpusar: de vanligaste orden förekommer mycket oftare än de flesta andra — i engelska korpus är artikeln "the" ofta ett tydligt exempel.
- Städers befolkning: när städer sorteras efter invånarantal följer ofta den n:te stadens storlek ungefär en invers relation mot n — en observation som noterades tidigt av Felix Auerbach och senare relaterades till Zipf.
- Företagsstorlekar, inkomster, webbtrafik och andra rankade storheter där en liten andel dominerar resten.
Tolkningar, generaliseringar och begränsningar
Det finns flera förklaringsförsök till varför Zipfs lag uppträder: mekanismer som preferential attachment ("den rike blir rikare"), optimeringsprinciper i kommunikation, stokastiska modeller och kombinatoriska/sekvensteorier. Inget av dessa ger ett entydigt, allmänt accepterat svar; ofta räcker olika mekanismer till i olika sammanhang.
Zipfs lag är också en specialfall av bredare klass av så kallade kraftlagar (power laws). En vanlig generalisering är Zipf–Mandelbrotlagen, som introducerar en förskjutningsparameter q: f_r \u221D 1/(r+q)^s. Denna form kan ge bättre anpassning i praktiska data där avvikelser förekommer i toppen av rankningen.
Hur man känner igen och prövar lagen
I empiriska studier plottas ofta frekvens mot rang i en log-log-graf; om punkterna ligger nära en rät linje med lutning nära -1 är detta stöd för en Zipf-liknande fördelning. Viktigt är att bedöma kvaliteten på data, urvalsbias och om ett annat s-värde eller en annan modell ger bättre förklaring.
Väsentliga fakta och noteringar
- Zipfs lag är i första hand empirisk — den anger ett mönster, inte en orsak.
- I språkstudier är observationen praktisk för textmodellering, informationskompression och korpuslingvistik.
- Generaliserade modeller och alternativa förklaringar gör att samma mönster kan tolkas mycket olika beroende på fält: se vidare litteratur och metodiska recensioner via ranganalys och avancerade statistiska modeller.
För vidare läsning och historiska källor om uppkomsten av begreppet och dess spridning inom olika vetenskaper, se introduktioner och översikter som behandlar både Zipfs originaltexter och efterföljande arbete inom statistik och komplexitetsteori. Mer information finns även i översiktsartiklar om empiriska kraftlagar och deras tillämpningar (översikt, teori, metodik).
Frågor och svar
F: Vad är Zipfs lag?
S: Zipfs lag är en empirisk lag som säger att frekvensen av ett ord i ett stort urval är omvänt proportionell mot dess rang i frekvenstabellen.
F: Vem föreslog Zipfs lag?
S: Zipfs lag föreslogs först av George Kingsley Zipf, en lingvist.
F: Hur förklarar Zipfs lag ordfrekvensen i ett urval av engelska ord?
S: Enligt Zipfs lag förekommer det mest frekventa ordet i ett urval av engelska ord ungefär dubbelt så ofta som det näst mest frekventa ordet, tre gånger så ofta som det tredje mest frekventa ordet osv. Denna trend fortsätter när ordets rangordning minskar.
F: Hur många procent av alla ord utgör det mest frekvent förekommande ordet i ett urval av engelska ord?
S: I ett urval av engelska ord utgör det mest frekvent förekommande ordet ("the") nästan 7% av alla ord.
F: Vad är förhållandet mellan antalet ord som behövs för att representera halva urvalet och frekvensen av dessa ord?
S: Enligt Zipfs lag behövs det bara ca 135 ord för att motsvara hälften av alla ord i ett stort urval.
F: Vilka andra rangordningar uppvisar Zipfs lag?
S: Samma förhållande som Zipfs lag beskriver i frekvensen av ord förekommer i andra rangordningar som inte är relaterade till språk, till exempel befolkningsrankningen av städer i olika länder, företagsstorlekar och inkomstrankning.
F: Vem lade märke till hur fördelningen såg ut i rankningen av städer efter befolkning?
S: Uppkomsten av fördelningen i rankningar av städer efter befolkning noterades först av Felix Auerbach 1913.
Relaterade artiklar
Författare
AlegsaOnline.com Zipfs lag: rang–frekvensfördelning i språk och andra system Leandro Alegsa
URL: https://sv.alegsaonline.com/art/110649
Källor
- books.google.com : P. 139